 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Subspace Dictionary Learning
Paper and Code
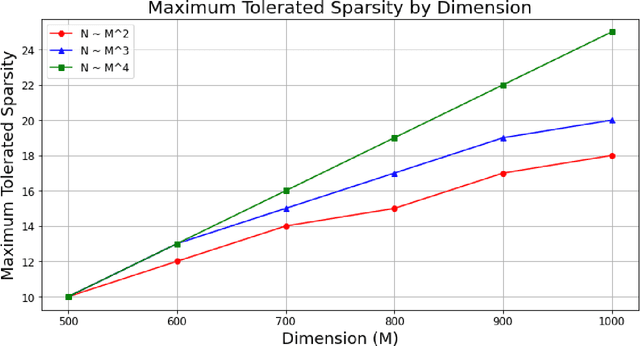
\textit{Dictionary learning}, the problem of recovering a sparsely used matrix $\mathbf{D} \in \mathbb{R}^{M \times K}$ and $N$ independent $K \times 1$ $s$-sparse vectors $\mathbf{X} \in \mathbb{R}^{K \times N}$ from samples of the form $\mathbf{Y} = \mathbf{D}\mathbf{X}$, is of increasing importance to applications in signal processing and data science. Early papers on provable dictionary learning identified that one can detect whether two samples $\mathbf{y}_i, \mathbf{y}_j$ share a common dictionary element by testing if their absolute inner product (correlation) exceeds a certain threshold: $|\left\langle \mathbf{y}_i, \mathbf{y}_j \right\rangle| > \tau$. These correlation-based methods work well when sparsity is small, but suffer from declining performance when sparsity grows faster than $\sqrt{M}$; as a result, such methods were abandoned in the search for dictionary learning algorithms when sparsity is nearly linear in $M$. In this paper, we revisit correlation-based dictionary learning. Instead of seeking to recover individual dictionary atoms, we employ a spectral method to recover the subspace spanned by the dictionary atoms in the support of each sample. This approach circumvents the primary challenge encountered by previous correlation methods, namely that when sharing information between two samples it is difficult to tell \textit{which} dictionary element the two samples share. We prove that under a suitable random model the resulting algorithm recovers dictionaries in polynomial time for sparsity linear in $M$ up to log factors. Our results improve on the best known methods by achieving a decaying error bound in dimension $M$; the best previously known results for the overcomplete ($K > M$) setting achieve polynomial time linear regime only for constant error bounds. Numerical simulations confirm our results.