 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Semantic ConvNet-Based Visual Place Recognition
Paper and Code
Sep 17, 2019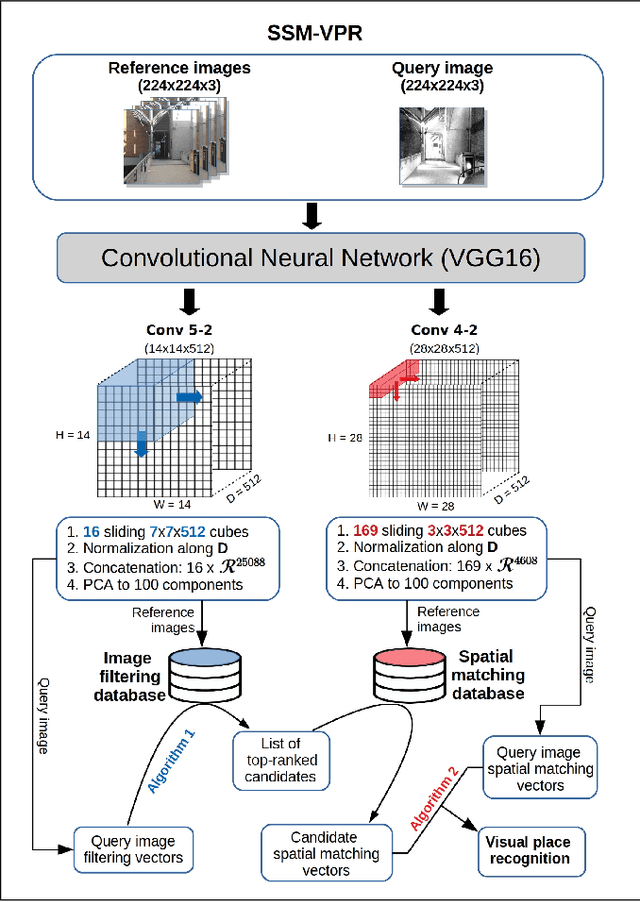
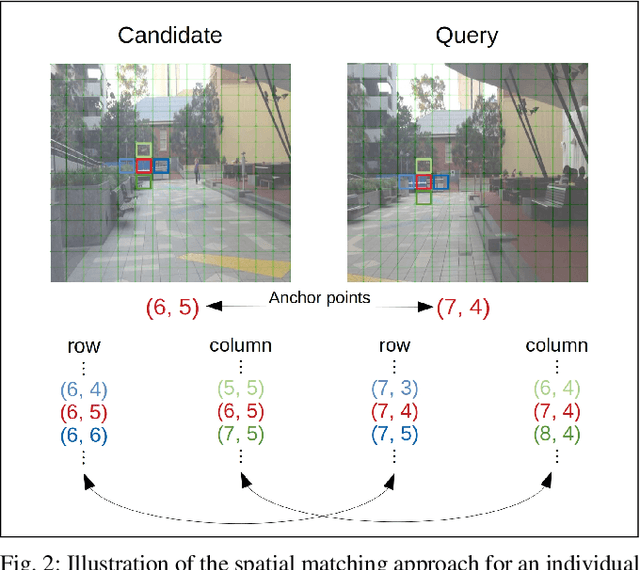

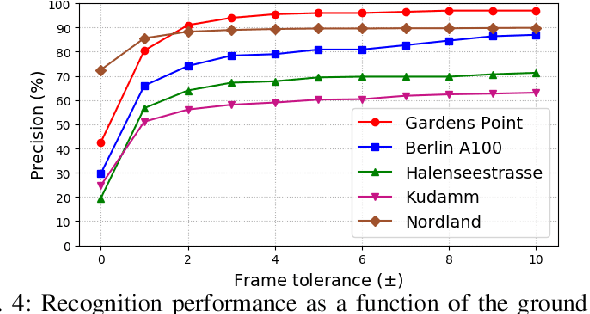
We present a Visual Place Recognition system that follows the two-stage format common to image retrieval pipelines. The system encodes images of places by employing the activations of different layers of a pre-trained, off-the-shelf, VGG16 Convolutional Neural Network (CNN) architecture. In the first stage of our method and given a query image of a place, a number of top candidate images is retrieved from a previously stored database of places. In the second stage, we propose an exhaustive comparison of the query image against these candidates by encoding semantic and spatial information in the form of CNN features. Results from our approach outperform by a large margin state-of-the-art visual place recognition methods on five of the most commonly used benchmark datasets. The performance gain is especially remarkable on the most challenging datasets, with more than a twofold recognition improvement with respect to the latest published work.