Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPatchGAN: A Statistical Feature Based Discriminator for Unsupervised Image-to-Image Translation
Paper and Code
Mar 30, 2021
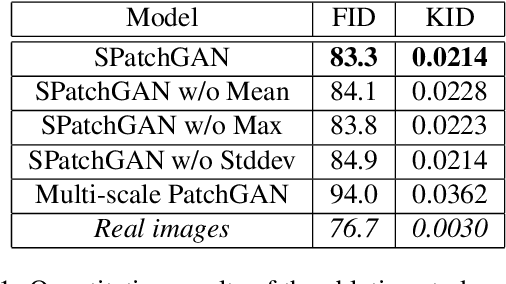
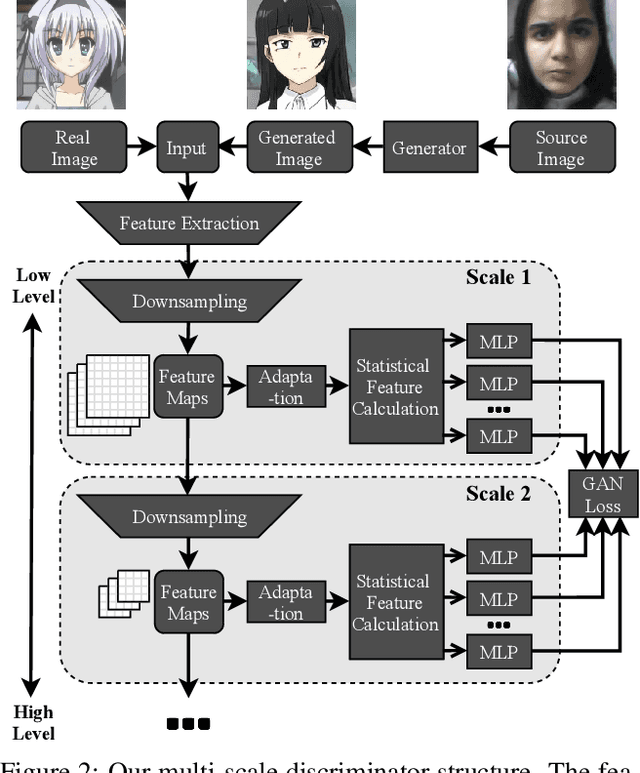
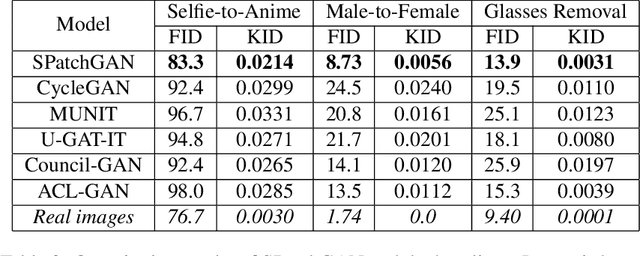
For unsupervised image-to-image translation, we propose a discriminator architecture which focuses on the statistical features instead of individual patches. The network is stabilized by distribution matching of key statistical features at multiple scales. Unlike the existing methods which impose more and more constraints on the generator, our method facilitates the shape deformation and enhances the fine details with a greatly simplified framework. We show that the proposed method outperforms the existing state-of-the-art models in various challenging applications including selfie-to-anime, male-to-female and glasses removal. The code will be made publicly available.
View paper on