 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity by Redundancy: Solving $L_1$ with a Simple Reparametrization
Paper and Code

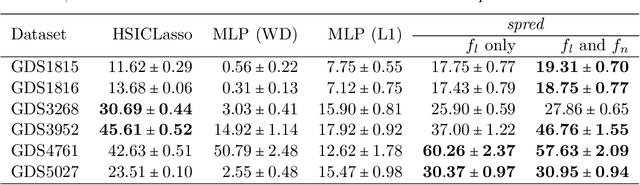
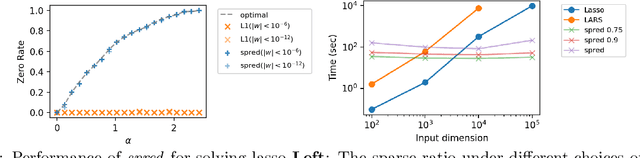

We identify and prove a general principle: $L_1$ sparsity can be achieved using a redundant parametrization plus $L_2$ penalty. Our results lead to a simple algorithm, \textit{spred}, that seamlessly integrates $L_1$ regularization into any modern deep learning framework. Practically, we demonstrate (1) the efficiency of \textit{spred} in optimizing conventional tasks such as lasso and sparse coding, (2) benchmark our method for nonlinear feature selection of six gene selection tasks, and (3) illustrate the usage of the method for achieving structured and unstructured sparsity in deep learning in an end-to-end manner. Conceptually, our result bridges the gap in understanding the inductive bias of the redundant parametrization common in deep learning and conventional statistical learning.