 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparser, Better, Deeper, Stronger: Improving Sparse Training with Exact Orthogonal Initialization
Paper and Code
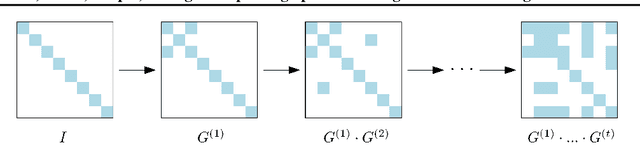
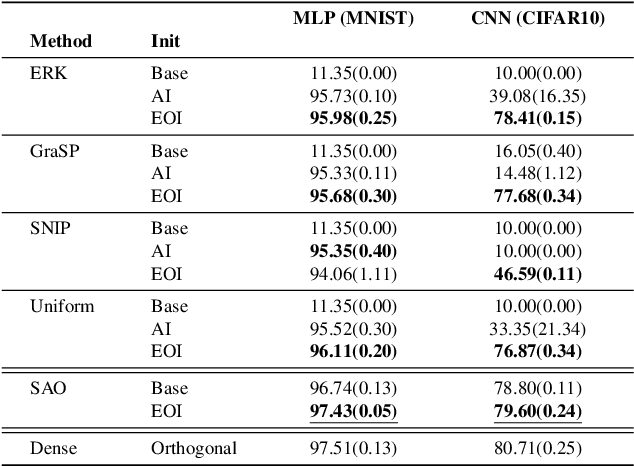
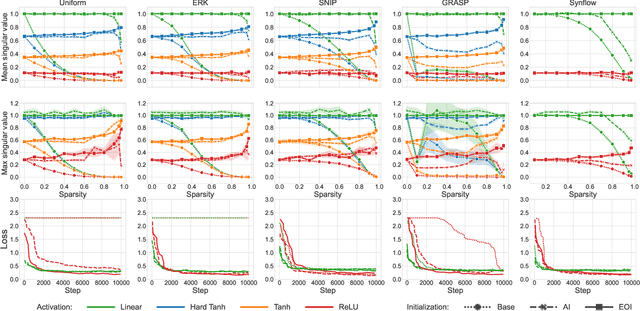
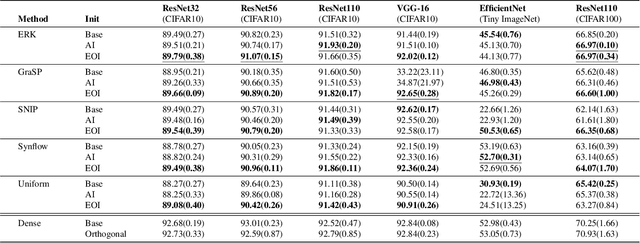
Static sparse training aims to train sparse models from scratch, achieving remarkable results in recent years. A key design choice is given by the sparse initialization, which determines the trainable sub-network through a binary mask. Existing methods mainly select such mask based on a predefined dense initialization. Such an approach may not efficiently leverage the mask's potential impact on the optimization. An alternative direction, inspired by research into dynamical isometry, is to introduce orthogonality in the sparse subnetwork, which helps in stabilizing the gradient signal. In this work, we propose Exact Orthogonal Initialization (EOI), a novel sparse orthogonal initialization scheme based on composing random Givens rotations. Contrary to other existing approaches, our method provides exact (not approximated) orthogonality and enables the creation of layers with arbitrary densities. We demonstrate the superior effectiveness and efficiency of EOI through experiments, consistently outperforming common sparse initialization techniques. Our method enables training highly sparse 1000-layer MLP and CNN networks without residual connections or normalization techniques, emphasizing the crucial role of weight initialization in static sparse training alongside sparse mask selection. The code is available at https://github.com/woocash2/sparser-better-deeper-stronger