Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaces of Clusterings
Paper and Code
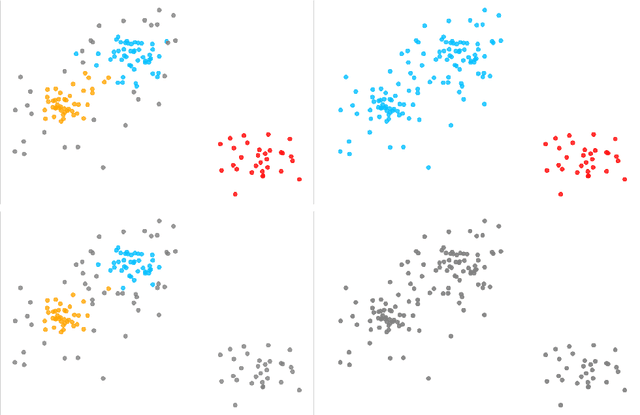
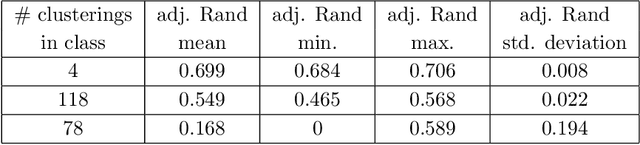
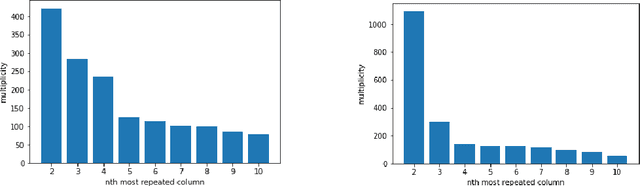
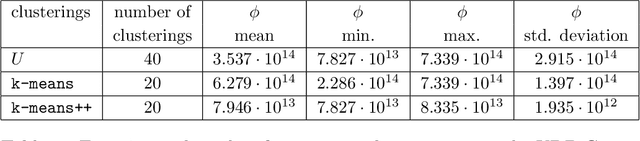
We propose two algorithms to cluster a set of clusterings of a fixed dataset, such as sets of clusterings produced by running a clustering algorithm with a range of parameters, or with many initializations. We use these to study the effects of varying the parameters of HDBSCAN, and to study methods for initializing $k$-means.
* 13 pages
View paper on