 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Mixing and Separation Robust Audio Steganography
Paper and Code
Oct 11, 2021


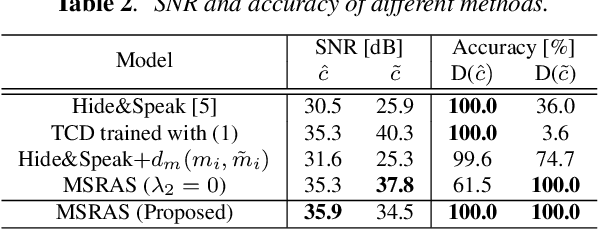
Audio steganography aims at concealing secret information in carrier audio with imperceptible modification on the carrier. Although previous works addressed the robustness of concealed message recovery against distortions introduced during transmission, they do not address the robustness against aggressive editing such as mixing of other audio sources and source separation. In this work, we propose for the first time a steganography method that can embed information into individual sound sources in a mixture such as instrumental tracks in music. To this end, we propose a time-domain model and curriculum learning essential to learn to decode the concealed message from the separated sources. Experimental results show that the proposed method successfully conceals the information in an imperceptible perturbation and that the information can be correctly recovered even after mixing of other sources and separation by a source separation algorithm. Furthermore, we show that the proposed method can be applied to multiple sources simultaneously without interfering with the decoder for other sources even after the sources are mixed and separated.