 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMTimeS: Self Organizing Maps for Time Series Clustering and its Application to Serious Illness Conversations
Paper and Code
Aug 26, 2021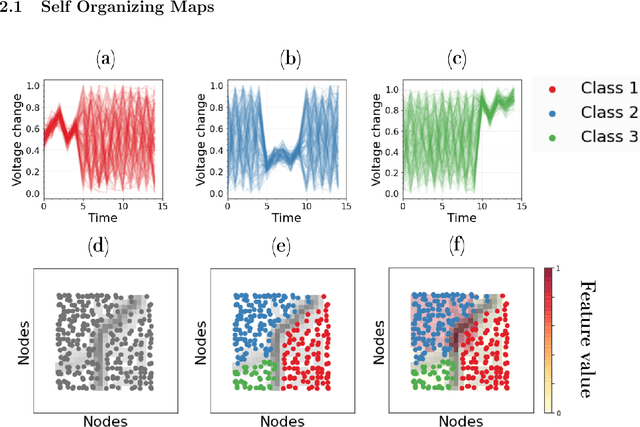
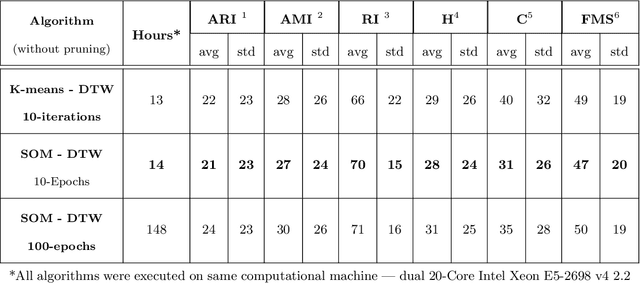
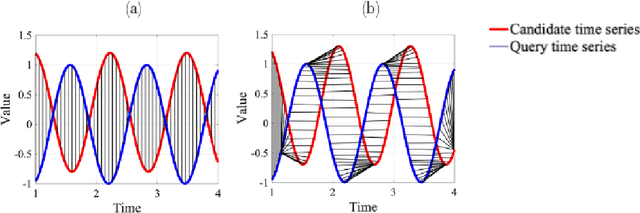
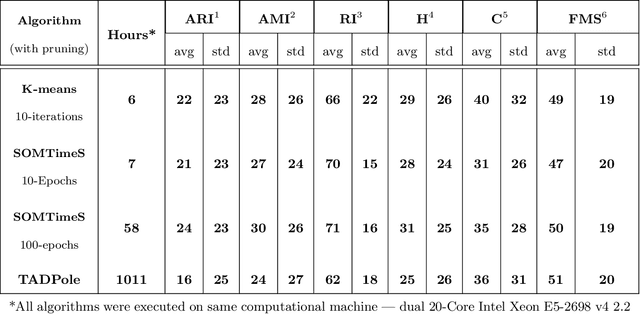
There is an increasing demand for scalable algorithms capable of clustering and analyzing large time series datasets. The Kohonen self-organizing map (SOM) is a type of unsupervised artificial neural network for visualizing and clustering complex data, reducing the dimensionality of data, and selecting influential features. Like all clustering methods, the SOM requires a measure of similarity between input data (in this work time series). Dynamic time warping (DTW) is one such measure, and a top performer given that it accommodates the distortions when aligning time series. Despite its use in clustering, DTW is limited in practice because it is quadratic in runtime complexity with the length of the time series data. To address this, we present a new DTW-based clustering method, called SOMTimeS (a Self-Organizing Map for TIME Series), that scales better and runs faster than other DTW-based clustering algorithms, and has similar performance accuracy. The computational performance of SOMTimeS stems from its ability to prune unnecessary DTW computations during the SOM's training phase. We also implemented a similar pruning strategy for K-means for comparison with one of the top performing clustering algorithms. We evaluated the pruning effectiveness, accuracy, execution time and scalability on 112 benchmark time series datasets from the University of California, Riverside classification archive. We showed that for similar accuracy, the speed-up achieved for SOMTimeS and K-means was 1.8x on average; however, rates varied between 1x and 18x depending on the dataset. SOMTimeS and K-means pruned 43% and 50% of the total DTW computations, respectively. We applied SOMtimeS to natural language conversation data collected as part of a large healthcare cohort study of patient-clinician serious illness conversations to demonstrate the algorithm's utility with complex, temporally sequenced phenomena.