 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome Properties of Preposition and Subordinate Conjunction Attachments
Paper and Code
Aug 20, 1998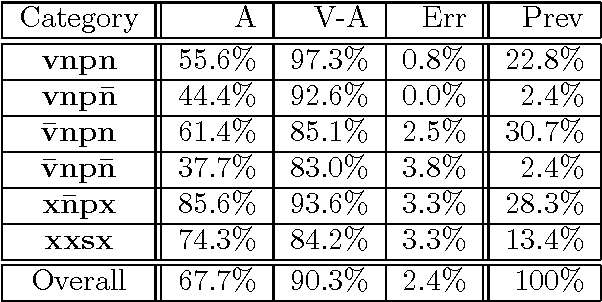
Determining the attachments of prepositions and subordinate conjunctions is a key problem in parsing natural language. This paper presents a trainable approach to making these attachments through transformation sequences and error-driven learning. Our approach is broad coverage, and accounts for roughly three times the attachment cases that have previously been handled by corpus-based techniques. In addition, our approach is based on a simplified model of syntax that is more consistent with the practice in current state-of-the-art language processing systems. This paper sketches syntactic and algorithmic details, and presents experimental results on data sets derived from the Penn Treebank. We obtain an attachment accuracy of 75.4% for the general case, the first such corpus-based result to be reported. For the restricted cases previously studied with corpus-based methods, our approach yields an accuracy comparable to current work (83.1%).