 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILES Enumeration as Data Augmentation for Neural Network Modeling of Molecules
Paper and Code
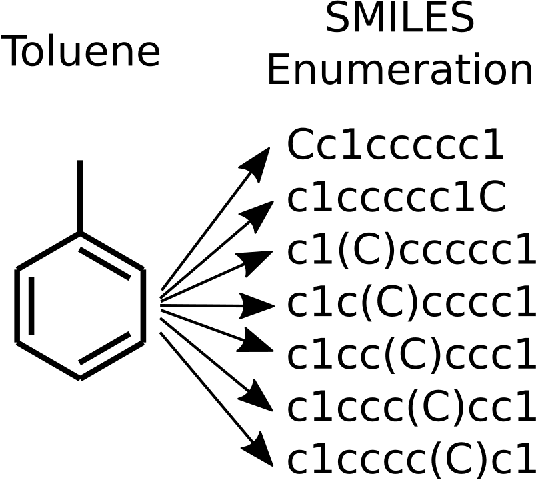
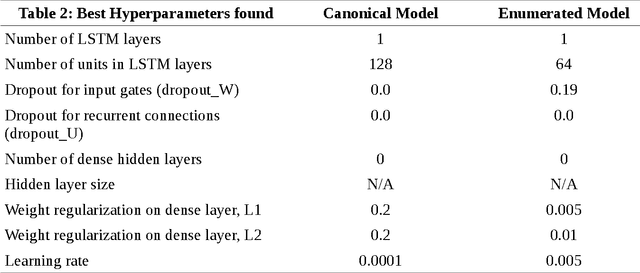
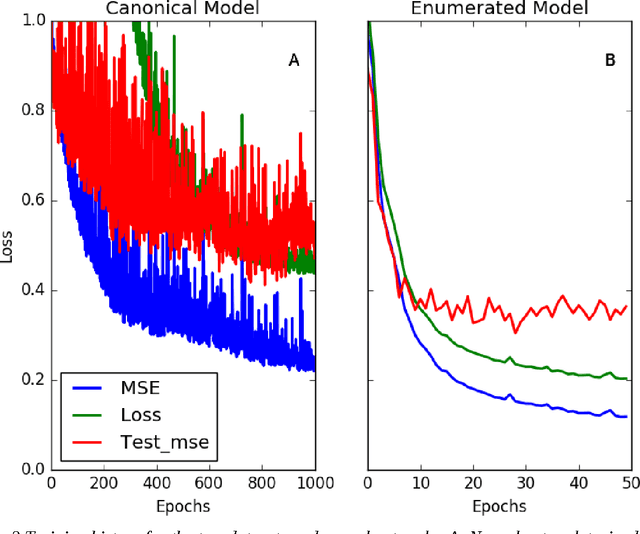
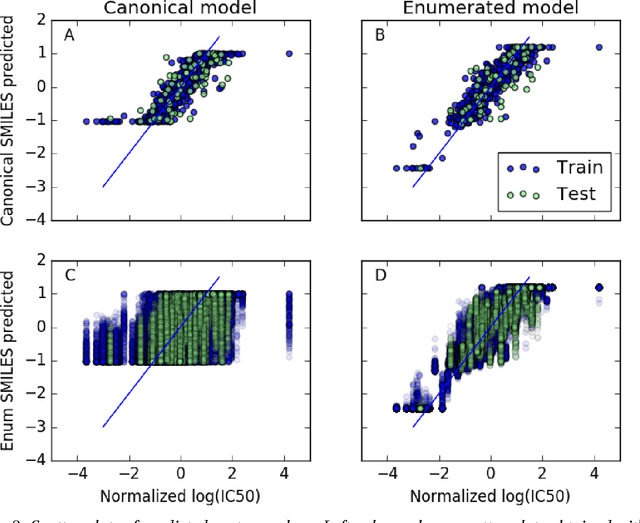
Simplified Molecular Input Line Entry System (SMILES) is a single line text representation of a unique molecule. One molecule can however have multiple SMILES strings, which is a reason that canonical SMILES have been defined, which ensures a one to one correspondence between SMILES string and molecule. Here the fact that multiple SMILES represent the same molecule is explored as a technique for data augmentation of a molecular QSAR dataset modeled by a long short term memory (LSTM) cell based neural network. The augmented dataset was 130 times bigger than the original. The network trained with the augmented dataset shows better performance on a test set when compared to a model built with only one canonical SMILES string per molecule. The correlation coefficient R2 on the test set was improved from 0.56 to 0.66 when using SMILES enumeration, and the root mean square error (RMS) likewise fell from 0.62 to 0.55. The technique also works in the prediction phase. By taking the average per molecule of the predictions for the enumerated SMILES a further improvement to a correlation coefficient of 0.68 and a RMS of 0.52 was found.