 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLYKLatent, a Learning Framework for Facial Features Estimation
Paper and Code
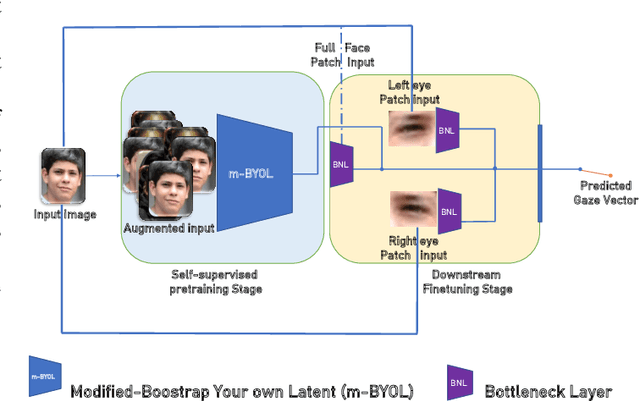
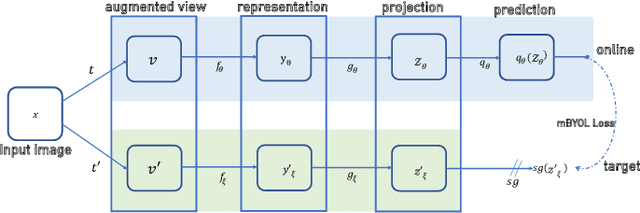

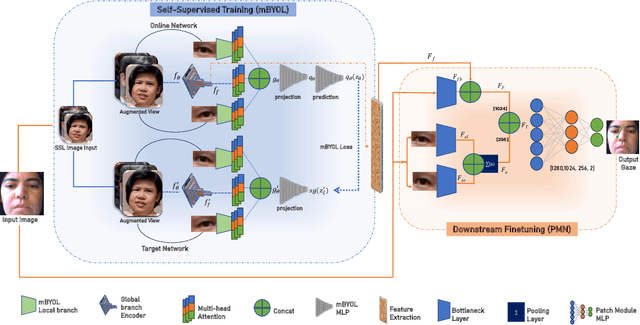
In this research, we present SLYKLatent, a novel approach for enhancing gaze estimation by addressing appearance instability challenges in datasets due to aleatoric uncertainties, covariant shifts, and test domain generalization. SLYKLatent utilizes Self-Supervised Learning for initial training with facial expression datasets, followed by refinement with a patch-based tri-branch network and an inverse explained variance-weighted training loss function. Our evaluation on benchmark datasets achieves an 8.7% improvement on Gaze360, rivals top MPIIFaceGaze results, and leads on a subset of ETH-XGaze by 13%, surpassing existing methods by significant margins. Adaptability tests on RAF-DB and Affectnet show 86.4% and 60.9% accuracies, respectively. Ablation studies confirm the effectiveness of SLYKLatent's novel components. This approach has strong potential in human-robot interaction.