Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlowly Changing Adversarial Bandit Algorithms are Provably Efficient for Discounted MDPs
Paper and Code
May 18, 2022
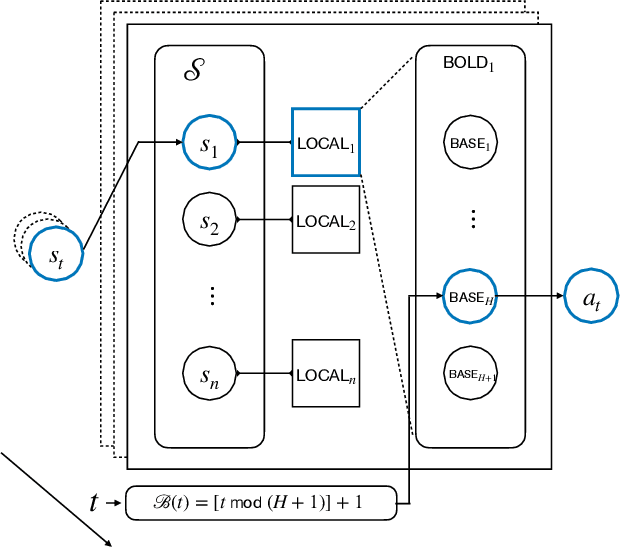
Reinforcement learning (RL) generalizes bandit problems with additional difficulties on longer planning horzion and unknown transition kernel. We show that, under some mild assumptions, \textbf{any} slowly changing adversarial bandit algorithm enjoys near-optimal regret in adversarial bandits can achieve near-optimal (expected) regret in non-episodic discounted MDPs. The slowly changing property required by our generalization is mild, see e.g. (Even-Dar et al. 2009, Neu et al. 2010), we also show, for example, \expt~(Auer et al. 2002) is slowly changing and enjoys near-optimal regret in MDPs.
View paper on