 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Contrastive Networks: A Contrastive Approach for Representing Objects
Paper and Code
Jul 18, 2020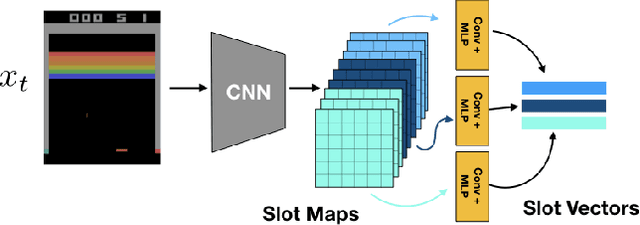
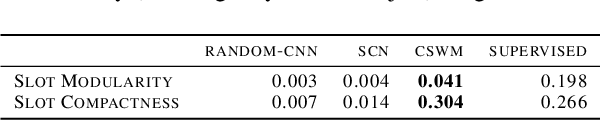
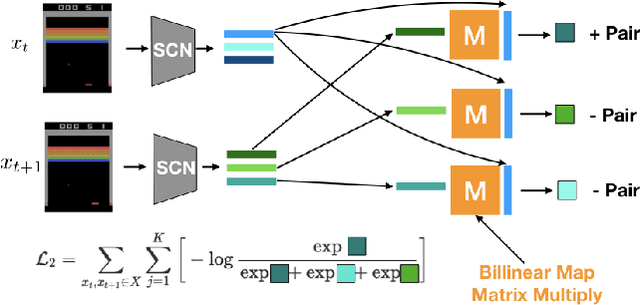

Unsupervised extraction of objects from low-level visual data is an important goal for further progress in machine learning. Existing approaches for representing objects without labels use structured generative models with static images. These methods focus a large amount of their capacity on reconstructing unimportant background pixels, missing low contrast or small objects. Conversely, we present a new method that avoids losses in pixel space and over-reliance on the limited signal a static image provides. Our approach takes advantage of objects' motion by learning a discriminative, time-contrastive loss in the space of slot representations, attempting to force each slot to not only capture entities that move, but capture distinct objects from the other slots. Moreover, we introduce a new quantitative evaluation metric to measure how "diverse" a set of slot vectors are, and use it to evaluate our model on 20 Atari games.