Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSJ_AJ@DravidianLangTech-EACL2021: Task-Adaptive Pre-Training of Multilingual BERT models for Offensive Language Identification
Paper and Code
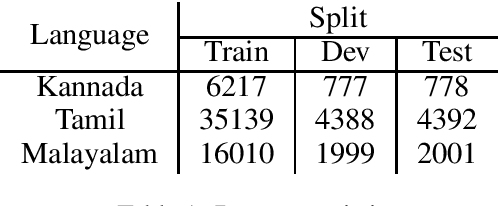
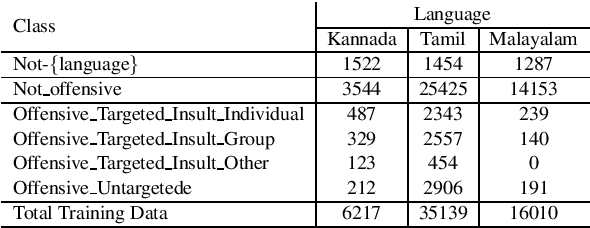
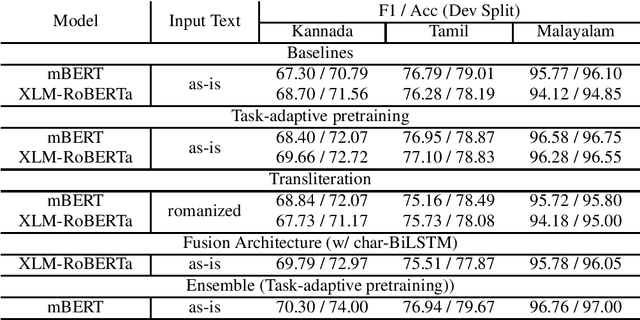

In this paper we present our submission for the EACL 2021-Shared Task on Offensive Language Identification in Dravidian languages. Our final system is an ensemble of mBERT and XLM-RoBERTa models which leverage task-adaptive pre-training of multilingual BERT models with a masked language modeling objective. Our system was ranked 1st for Kannada, 2nd for Malayalam and 3rd for Tamil.
View paper on