 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSize Independent Neural Transfer for RDDL Planning
Paper and Code
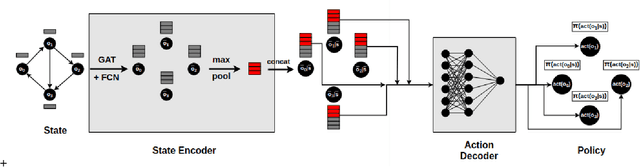
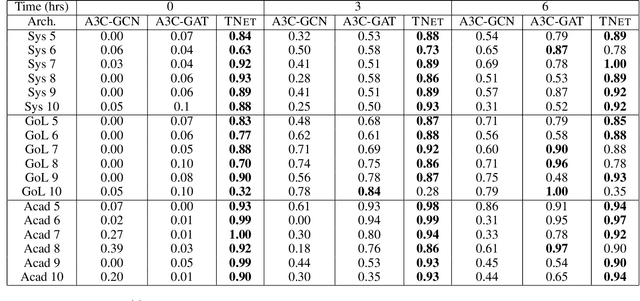
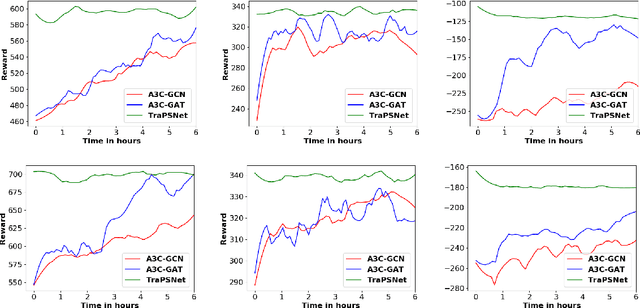
Neural planners for RDDL MDPs produce deep reactive policies in an offline fashion. These scale well with large domains, but are sample inefficient and time-consuming to train from scratch for each new problem. To mitigate this, recent work has studied neural transfer learning, so that a generic planner trained on other problems of the same domain can rapidly transfer to a new problem. However, this approach only transfers across problems of the same size. We present the first method for neural transfer of RDDL MDPs that can transfer across problems of different sizes. Our architecture has two key innovations to achieve size independence: (1) a state encoder, which outputs a fixed length state embedding by max pooling over varying number of object embeddings, (2) a single parameter-tied action decoder that projects object embeddings into action probabilities for the final policy. On the two challenging RDDL domains of SysAdmin and Game Of Life, our approach powerfully transfers across problem sizes and has superior learning curves over training from scratch.