 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinkLoRA: Enhanced Efficiency and Chat Capabilities for Long-Context Large Language Models
Paper and Code
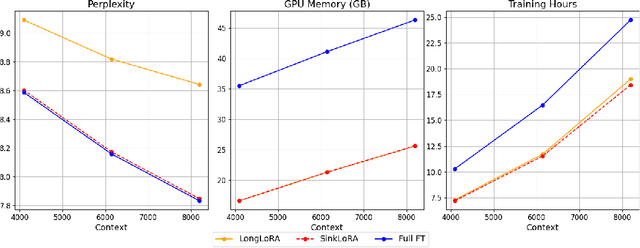
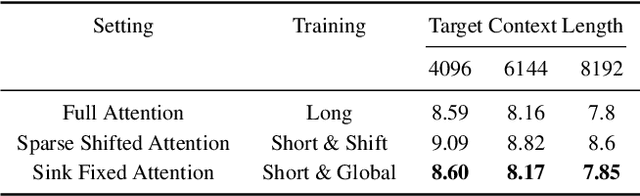
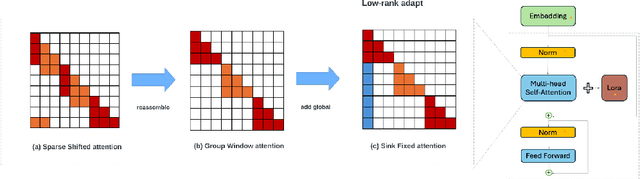
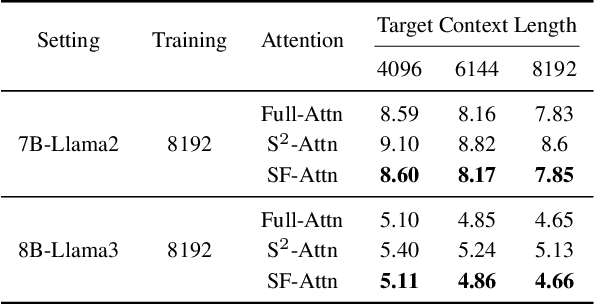
Extending the functionality of the Transformer model to accommodate longer sequence lengths has become a critical challenge. This extension is crucial not only for improving tasks such as language translation and long-context processing but also for enabling novel applications like chatbots, code generation, and multimedia content creation. The primary obstacle is the self-attention mechanism, which scales quadratically with sequence length in terms of computation time and memory requirements. LongLoRA proposed shifted sparse attention (S\(^2\)-Attn), effectively enabling context extension and leading to non-trivial computation savings with similar performance to fine-tuning with vanilla attention. However, LongLoRA is still not as efficient as vanilla attention, reaching only 39\% of the perplexity improvement compared to full attention. This inefficiency is due to the cyclic shift applied within different attention head patterns, causing either chaos in the attention head structure or unnecessary information exchange between token groups. To address these issues, We propose \textbf{SinkLoRA}, which features better work partitioning. Specifically, (1) we developed SF-Attn with a segmentation and reassembly algorithm to proportionally return cyclically shifted groups of attention heads to their un-shifted state together with global attention of "sink attention tokens", achieving 92\% of the perplexity improvement compared to full attention after fine tuning, and (2) applied a SOTA KV cache compression algorithm H$_2$O to accelerate inference. Furthermore, We conducted supervised fine-tuning with SinkLoRA using a self collected LongAlpaca-plus dataset. All our code, models, datasets, and demos are available at \url{https://github.com/Dexter-GT-86/SinkLoRA}.