 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINCERE: Supervised Information Noise-Contrastive Estimation REvisited
Paper and Code

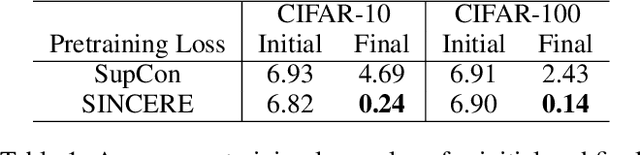
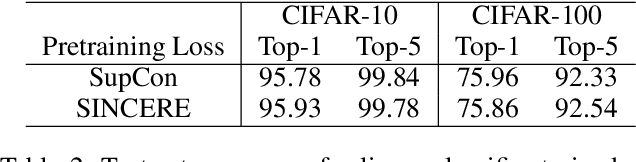
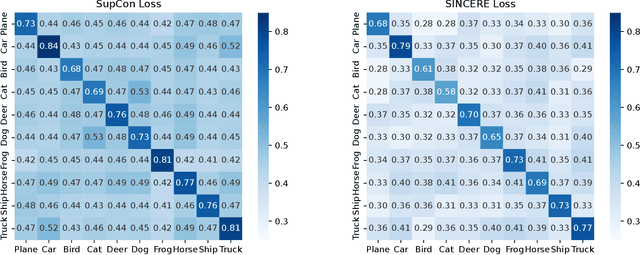
The information noise-contrastive estimation (InfoNCE) loss function provides the basis of many self-supervised deep learning methods due to its strong empirical results and theoretic motivation. Previous work suggests a supervised contrastive (SupCon) loss to extend InfoNCE to learn from available class labels. This SupCon loss has been widely-used due to reports of good empirical performance. However, in this work we suggest that the specific SupCon loss formulated by prior work has questionable theoretic justification, because it can encourage images from the same class to repel one another in the learned embedding space. This problematic behavior gets worse as the number of inputs sharing one class label increases. We propose the Supervised InfoNCE REvisited (SINCERE) loss as a remedy. SINCERE is a theoretically justified solution for a supervised extension of InfoNCE that never causes images from the same class to repel one another. We further show that minimizing our new loss is equivalent to maximizing a bound on the KL divergence between class conditional embedding distributions. We compare SINCERE and SupCon losses in terms of learning trajectories during pretraining and in ultimate linear classifier performance after finetuning. Our proposed SINCERE loss better separates embeddings from different classes during pretraining while delivering competitive accuracy.