 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimSCOOD: Systematic Analysis of Out-of-Distribution Behavior of Source Code Models
Paper and Code
Oct 10, 2022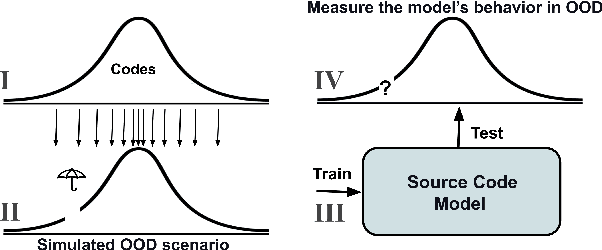

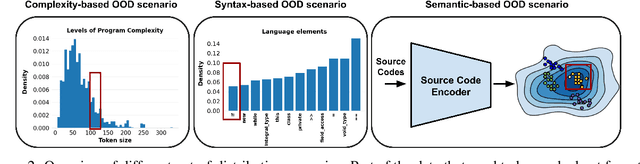
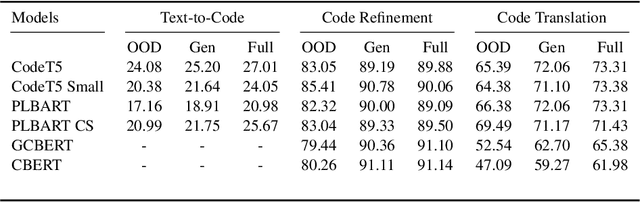
While large code datasets have become available in recent years, acquiring representative training data with full coverage of general code distribution remains challenging due to the compositional nature of code and the complexity of software. This leads to the out-of-distribution (OOD) issues with unexpected model inference behaviors that have not been systematically studied yet. We contribute the first systematic approach that simulates various OOD scenarios along different dimensions of data properties and investigates the model behaviors in such scenarios. Our extensive studies on six state-of-the-art models for three code generation tasks expose several failure modes caused by the out-of-distribution issues. It thereby provides insights and sheds light for future research in terms of generalization, robustness, and inductive biases of source code models.