 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplicity bias and optimization threshold in two-layer ReLU networks
Paper and Code
Oct 03, 2024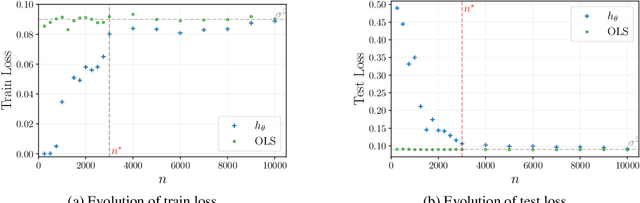
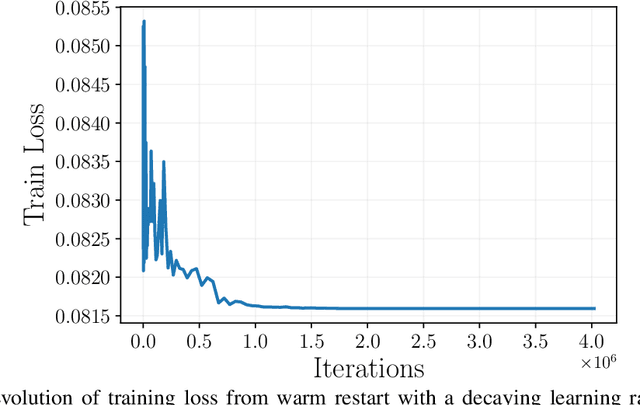
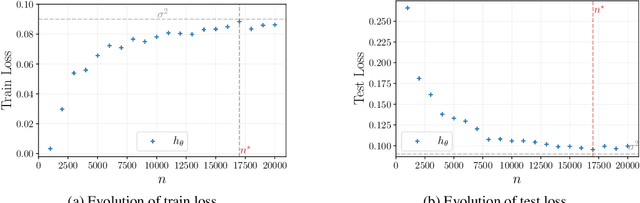
Understanding generalization of overparametrized neural networks remains a fundamental challenge in machine learning. Most of the literature mostly studies generalization from an interpolation point of view, taking convergence of parameters towards a global minimum of the training loss for granted. While overparametrized architectures indeed interpolated the data for typical classification tasks, this interpolation paradigm does not seem valid anymore for more complex tasks such as in-context learning or diffusion. Instead for such tasks, it has been empirically observed that the trained models goes from global minima to spurious local minima of the training loss as the number of training samples becomes larger than some level we call optimization threshold. While the former yields a poor generalization to the true population loss, the latter was observed to actually correspond to the minimiser of this true loss. This paper explores theoretically this phenomenon in the context of two-layer ReLU networks. We demonstrate that, despite overparametrization, networks often converge toward simpler solutions rather than interpolating the training data, which can lead to a drastic improvement on the test loss with respect to interpolating solutions. Our analysis relies on the so called early alignment phase, during which neurons align towards specific directions. This directional alignment, which occurs in the early stage of training, leads to a simplicity bias, wherein the network approximates the ground truth model without converging to the global minimum of the training loss. Our results suggest that this bias, resulting in an optimization threshold from which interpolation is not reached anymore, is beneficial and enhances the generalization of trained models.