 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Open Stance Classification for Rumour Analysis
Paper and Code
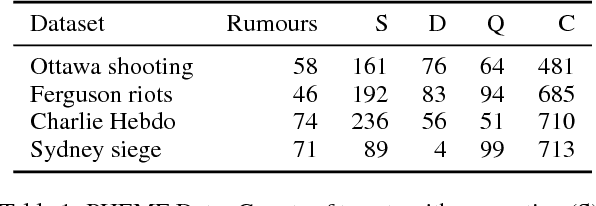
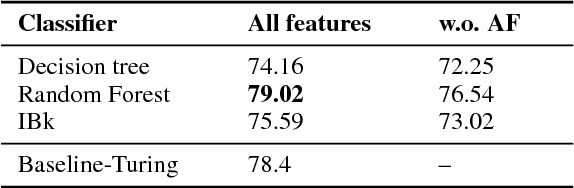


Stance classification determines the attitude, or stance, in a (typically short) text. The task has powerful applications, such as the detection of fake news or the automatic extraction of attitudes toward entities or events in the media. This paper describes a surprisingly simple and efficient classification approach to open stance classification in Twitter, for rumour and veracity classification. The approach profits from a novel set of automatically identifiable problem-specific features, which significantly boost classifier accuracy and achieve above state-of-the-art results on recent benchmark datasets. This calls into question the value of using complex sophisticated models for stance classification without first doing informed feature extraction.