Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple High Quality OoD Detection with L2 Normalization
Paper and Code
Jun 07, 2023
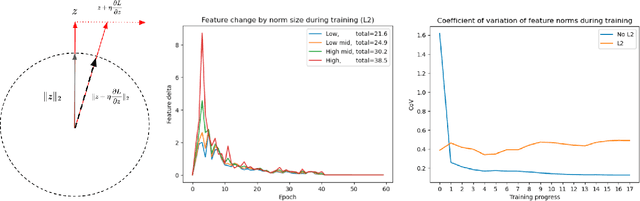
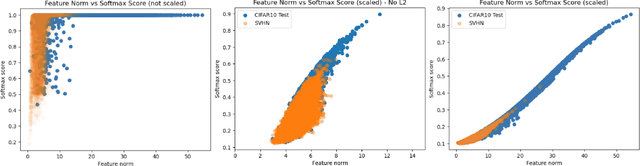
We propose a simple modification to standard ResNet architectures during training--L2 normalization over feature space--that produces results competitive with state-of-the-art Out-of-Distribution (OoD) detection performance. When L2 normalization is removed at test time, the L2 norm of feature vectors becomes a surprisingly good proxy for network uncertainty, whereas this behaviour is not nearly as effective when training without L2 normalization. Intuitively, familiar images result in large magnitude vectors, while unfamiliar images result in small magnitudes. Notably, this is achievable with almost no additional cost during training, and no cost at test time.
View paper on