 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-based Neighbor Selection for Graph LLMs
Paper and Code



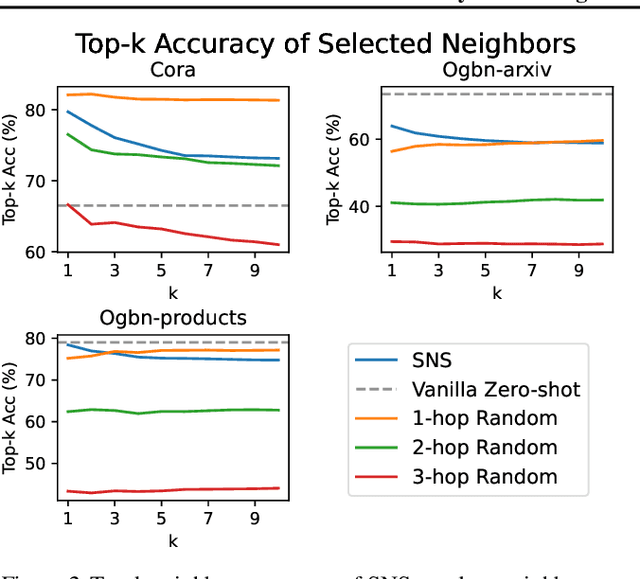
Text-attributed graphs (TAGs) present unique challenges for direct processing by Language Learning Models (LLMs), yet their extensive commonsense knowledge and robust reasoning capabilities offer great promise for node classification in TAGs. Prior research in this field has grappled with issues such as over-squashing, heterophily, and ineffective graph information integration, further compounded by inconsistencies in dataset partitioning and underutilization of advanced LLMs. To address these challenges, we introduce Similarity-based Neighbor Selection (SNS). Using SimCSE and advanced neighbor selection techniques, SNS effectively improves the quality of selected neighbors, thereby improving graph representation and alleviating issues like over-squashing and heterophily. Besides, as an inductive and training-free approach, SNS demonstrates superior generalization and scalability over traditional GNN methods. Our comprehensive experiments, adhering to standard dataset partitioning practices, demonstrate that SNS, through simple prompt interactions with LLMs, consistently outperforms vanilla GNNs and achieves state-of-the-art results on datasets like PubMed in node classification, showcasing LLMs' potential in graph structure understanding. Our research further underscores the significance of graph structure integration in LLM applications and identifies key factors for their success in node classification. Code is available at https://github.com/ruili33/SNS.