 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese x-vector reconstruction for domain adapted speaker recognition
Paper and Code
Jul 28, 2020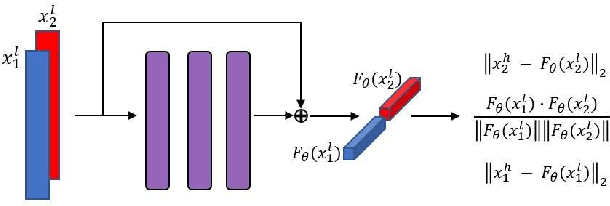

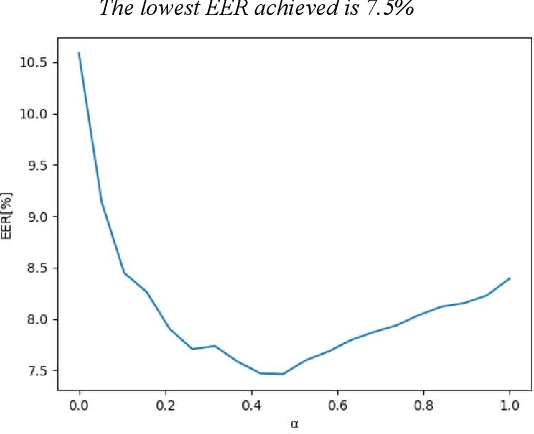
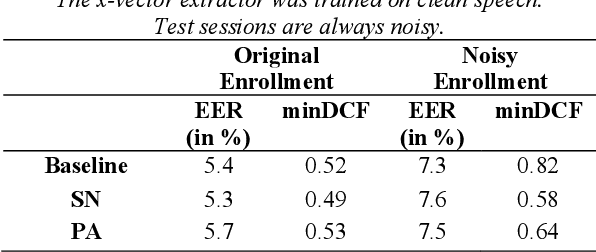
With the rise of voice-activated applications, the need for speaker recognition is rapidly increasing. The x-vector, an embedding approach based on a deep neural network (DNN), is considered the state-of-the-art when proper end-to-end training is not feasible. However, the accuracy significantly decreases when recording conditions (noise, sample rate, etc.) are mismatched, either between the x-vector training data and the target data or between enrollment and test data. We introduce the Siamese x-vector Reconstruction (SVR) for domain adaptation. We reconstruct the embedding of a higher quality signal from a lower quality counterpart using a lean auxiliary Siamese DNN. We evaluate our method on several mismatch scenarios and demonstrate significant improvement over the baseline.