 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese Networks for Large-Scale Author Identification
Paper and Code
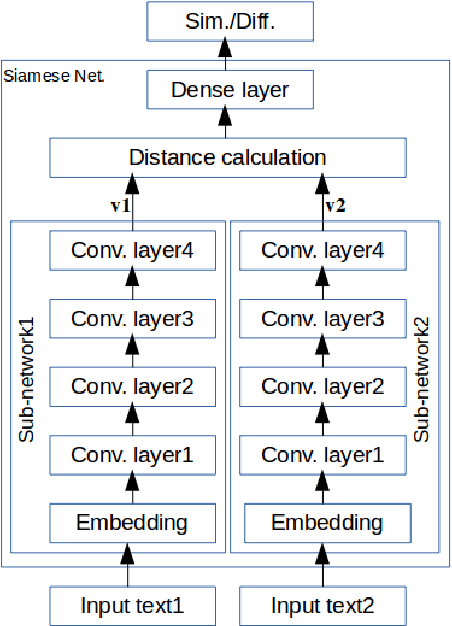
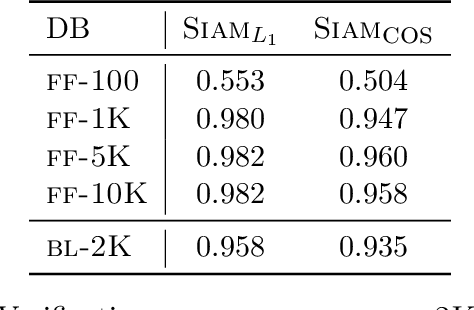
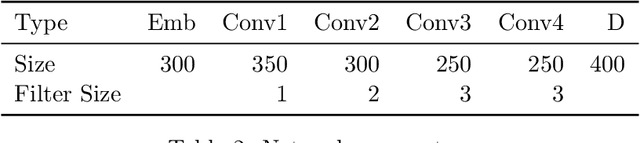
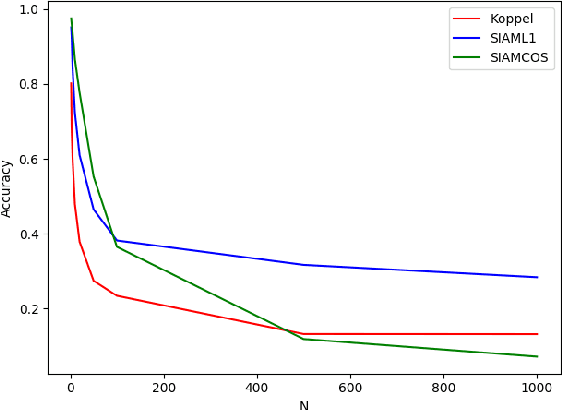
Authorship attribution is the process of identifying the author of a text. Classification-based approaches work well for small numbers of candidate authors, but only similarity-based methods are applicable for larger numbers of authors or for authors beyond the training set. While deep learning methods have been applied to classification-based approaches, applications to similarity-based applications have been limited, and most similarity-based methods only embody static notions of similarity. Siamese networks have been used to develop learned notions of similarity in one-shot image tasks, and also for tasks of mostly semantic relatedness in NLP. We examine their application to the stylistic task of authorship attribution on datasets with large numbers of authors, looking at multiple energy functions and neural network architectures, and show that they can substantially outperform both classification- and existing similarity-based approaches. We also find an unexpected relationship between choice of energy function and number of authors, in terms of performance.