 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow and Tell: Visually Explainable Deep Neural Nets via Spatially-Aware Concept Bottleneck Models
Paper and Code
Feb 27, 2025


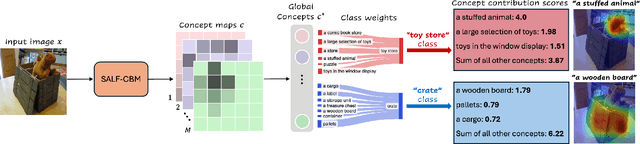
Modern deep neural networks have now reached human-level performance across a variety of tasks. However, unlike humans they lack the ability to explain their decisions by showing where and telling what concepts guided them. In this work, we present a unified framework for transforming any vision neural network into a spatially and conceptually interpretable model. We introduce a spatially-aware concept bottleneck layer that projects "black-box" features of pre-trained backbone models into interpretable concept maps, without requiring human labels. By training a classification layer over this bottleneck, we obtain a self-explaining model that articulates which concepts most influenced its prediction, along with heatmaps that ground them in the input image. Accordingly, we name this method "Spatially-Aware and Label-Free Concept Bottleneck Model" (SALF-CBM). Our results show that the proposed SALF-CBM: (1) Outperforms non-spatial CBM methods, as well as the original backbone, on a variety of classification tasks; (2) Produces high-quality spatial explanations, outperforming widely used heatmap-based methods on a zero-shot segmentation task; (3) Facilitates model exploration and debugging, enabling users to query specific image regions and refine the model's decisions by locally editing its concept maps.