Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHOMA at Parseme Shared Task on Automatic Identification of VMWEs: Neural Multiword Expression Tagging with High Generalisation
Paper and Code



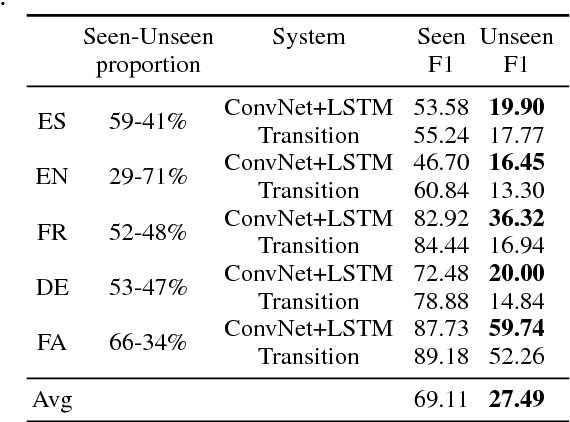
This paper presents a language-independent deep learning architecture adapted to the task of multiword expression (MWE) identification. We employ a neural architecture comprising of convolutional and recurrent layers with the addition of an optional CRF layer at the top. This system participated in the open track of the Parseme shared task on automatic identification of verbal MWEs due to the use of pre-trained wikipedia word embeddings. It outperformed all participating systems in both open and closed tracks with the overall macro-average MWE-based F1 score of 58.09 averaged among all languages. A particular strength of the system is its superior performance on unseen data entries.
View paper on