 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharper Bounds for $\ell_p$ Sensitivity Sampling
Paper and Code
Jun 01, 2023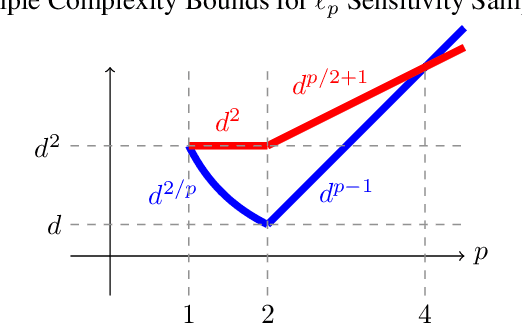
In large scale machine learning, random sampling is a popular way to approximate datasets by a small representative subset of examples. In particular, sensitivity sampling is an intensely studied technique which provides provable guarantees on the quality of approximation, while reducing the number of examples to the product of the VC dimension $d$ and the total sensitivity $\mathfrak S$ in remarkably general settings. However, guarantees going beyond this general bound of $\mathfrak S d$ are known in perhaps only one setting, for $\ell_2$ subspace embeddings, despite intense study of sensitivity sampling in prior work. In this work, we show the first bounds for sensitivity sampling for $\ell_p$ subspace embeddings for $p\neq 2$ that improve over the general $\mathfrak S d$ bound, achieving a bound of roughly $\mathfrak S^{2/p}$ for $1\leq p<2$ and $\mathfrak S^{2-2/p}$ for $2<p<\infty$. For $1\leq p<2$, we show that this bound is tight, in the sense that there exist matrices for which $\mathfrak S^{2/p}$ samples is necessary. Furthermore, our techniques yield further new results in the study of sampling algorithms, showing that the root leverage score sampling algorithm achieves a bound of roughly $d$ for $1\leq p<2$, and that a combination of leverage score and sensitivity sampling achieves an improved bound of roughly $d^{2/p}\mathfrak S^{2-4/p}$ for $2<p<\infty$. Our sensitivity sampling results yield the best known sample complexity for a wide class of structured matrices that have small $\ell_p$ sensitivity.