 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Reconstruction from Thoracoscopic Images using Self-supervised Virtual Learning
Paper and Code
Jan 25, 2023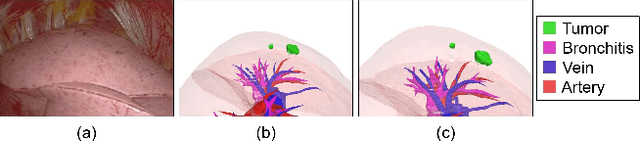
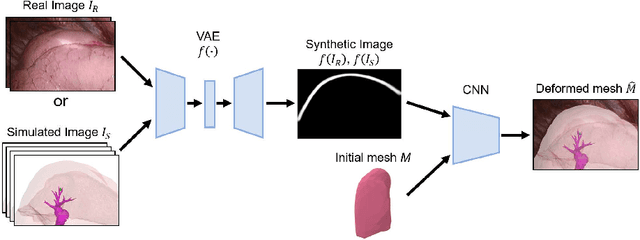
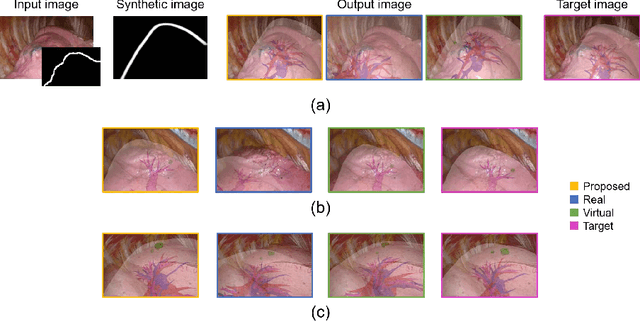
Intraoperative shape reconstruction of organs from endoscopic camera images is a complex yet indispensable technique for image-guided surgery. To address the uncertainty in reconstructing entire shapes from single-viewpoint occluded images, we propose a framework for generative virtual learning of shape reconstruction using image translation with common latent variables between simulated and real images. As it is difficult to prepare sufficient amount of data to learn the relationship between endoscopic images and organ shapes, self-supervised virtual learning is performed using simulated images generated from statistical shape models. However, small differences between virtual and real images can degrade the estimation performance even if the simulated images are regarded as equivalent by humans. To address this issue, a Variational Autoencoder is used to convert real and simulated images into identical synthetic images. In this study, we targeted the shape reconstruction of collapsed lungs from thoracoscopic images and confirmed that virtual learning could improve the similarity between real and simulated images. Furthermore, shape reconstruction error could be improved by 16.9%.