 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Preserving Facial Landmarks with Graph Attention Networks
Paper and Code
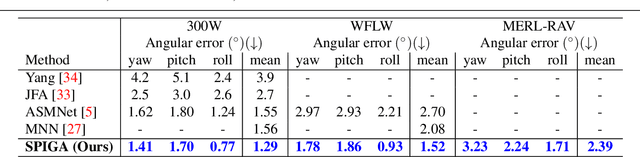

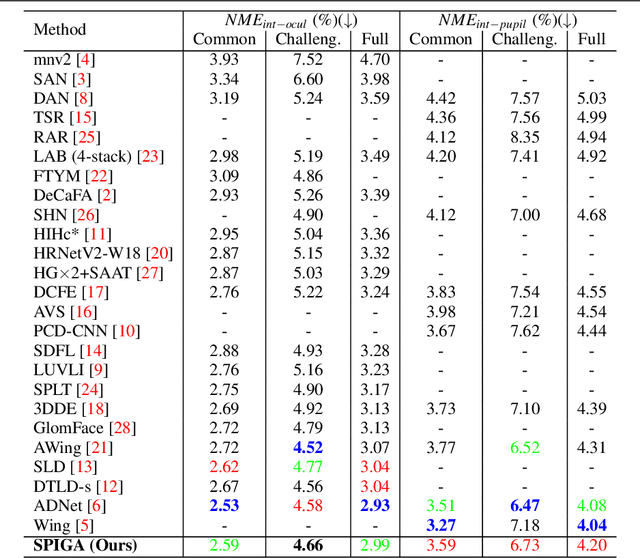
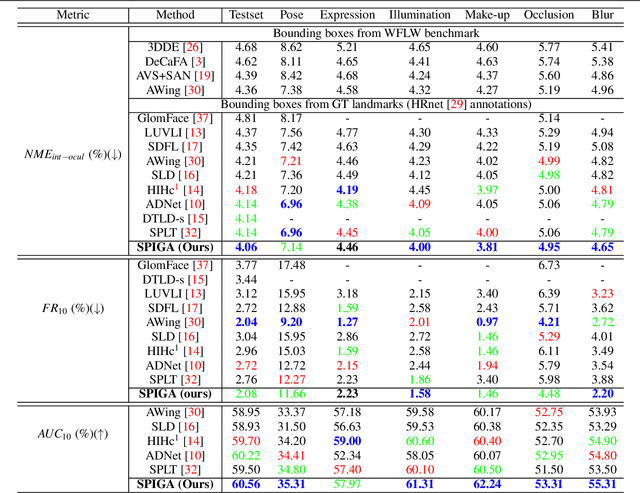
Top-performing landmark estimation algorithms are based on exploiting the excellent ability of large convolutional neural networks (CNNs) to represent local appearance. However, it is well known that they can only learn weak spatial relationships. To address this problem, we propose a model based on the combination of a CNN with a cascade of Graph Attention Network regressors. To this end, we introduce an encoding that jointly represents the appearance and location of facial landmarks and an attention mechanism to weigh the information according to its reliability. This is combined with a multi-task approach to initialize the location of graph nodes and a coarse-to-fine landmark description scheme. Our experiments confirm that the proposed model learns a global representation of the structure of the face, achieving top performance in popular benchmarks on head pose and landmark estimation. The improvement provided by our model is most significant in situations involving large changes in the local appearance of landmarks.