 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHADHO: Massively Scalable Hardware-Aware Distributed Hyperparameter Optimization
Paper and Code
Jan 22, 2018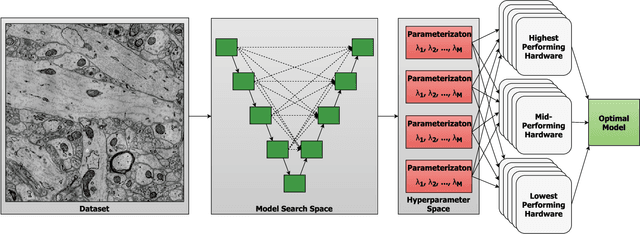
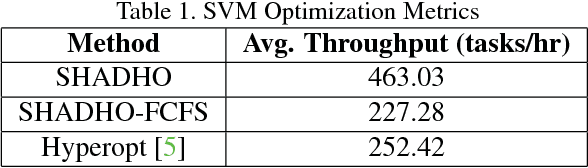
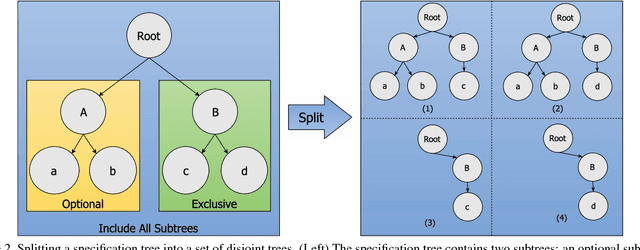

Computer vision is experiencing an AI renaissance, in which machine learning models are expediting important breakthroughs in academic research and commercial applications. Effectively training these models, however, is not trivial due in part to hyperparameters: user-configured values that control a model's ability to learn from data. Existing hyperparameter optimization methods are highly parallel but make no effort to balance the search across heterogeneous hardware or to prioritize searching high-impact spaces. In this paper, we introduce a framework for massively Scalable Hardware-Aware Distributed Hyperparameter Optimization (SHADHO). Our framework calculates the relative complexity of each search space and monitors performance on the learning task over all trials. These metrics are then used as heuristics to assign hyperparameters to distributed workers based on their hardware. We first demonstrate that our framework achieves double the throughput of a standard distributed hyperparameter optimization framework by optimizing SVM for MNIST using 150 distributed workers. We then conduct model search with SHADHO over the course of one week using 74 GPUs across two compute clusters to optimize U-Net for a cell segmentation task, discovering 515 models that achieve a lower validation loss than standard U-Net.