 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Learning of Movement Prediction in Dynamic Environments using LSTM Autoencoder
Paper and Code
Oct 12, 2018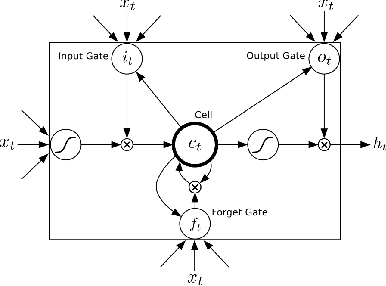

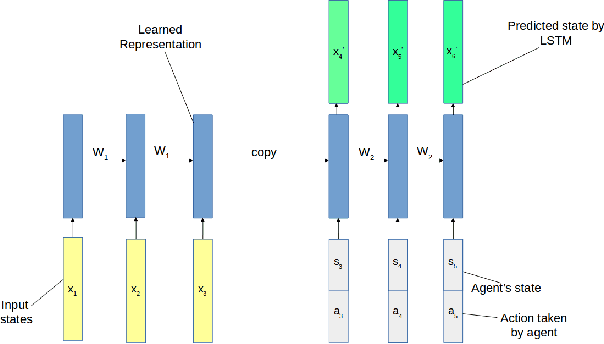

Predicting movement of objects while the action of learning agent interacts with the dynamics of the scene still remains a key challenge in robotics. We propose a multi-layer Long Short Term Memory (LSTM) autoendocer network that predicts future frames for a robot navigating in a dynamic environment with moving obstacles. The autoencoder network is composed of a state and action conditioned decoder network that reconstructs the future frames of video, conditioned on the action taken by the agent. The input image frames are first transformed into low dimensional feature vectors with a pre-trained encoder network and then reconstructed with the LSTM autoencoder network to generate the future frames. A virtual environment, based on the OpenAi-Gym framework for robotics, is used to gather training data and test the proposed network. The initial experiments show promising results indicating that these predicted frames can be used by an appropriate reinforcement learning framework in future to navigate around dynamic obstacles.