 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Feature Explanations for Anomaly Detection
Paper and Code
Feb 28, 2015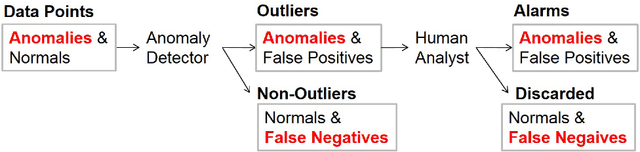
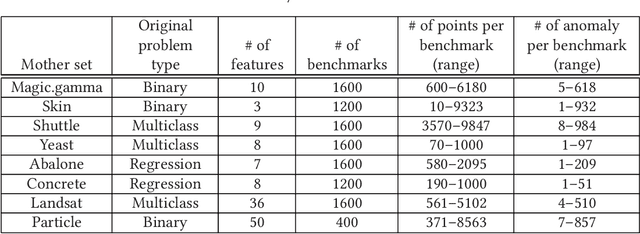
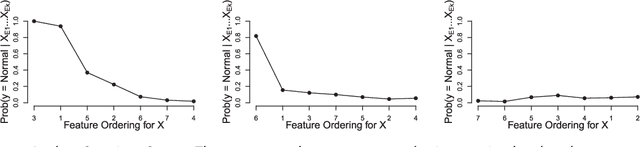

In many applications, an anomaly detection system presents the most anomalous data instance to a human analyst, who then must determine whether the instance is truly of interest (e.g. a threat in a security setting). Unfortunately, most anomaly detectors provide no explanation about why an instance was considered anomalous, leaving the analyst with no guidance about where to begin the investigation. To address this issue, we study the problems of computing and evaluating sequential feature explanations (SFEs) for anomaly detectors. An SFE of an anomaly is a sequence of features, which are presented to the analyst one at a time (in order) until the information contained in the highlighted features is enough for the analyst to make a confident judgement about the anomaly. Since analyst effort is related to the amount of information that they consider in an investigation, an explanation's quality is related to the number of features that must be revealed to attain confidence. One of our main contributions is to present a novel framework for large scale quantitative evaluations of SFEs, where the quality measure is based on analyst effort. To do this we construct anomaly detection benchmarks from real data sets along with artificial experts that can be simulated for evaluation. Our second contribution is to evaluate several novel explanation approaches within the framework and on traditional anomaly detection benchmarks, offering several insights into the approaches.