 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Classification with Empirically Observed Statistics
Paper and Code
Dec 03, 2019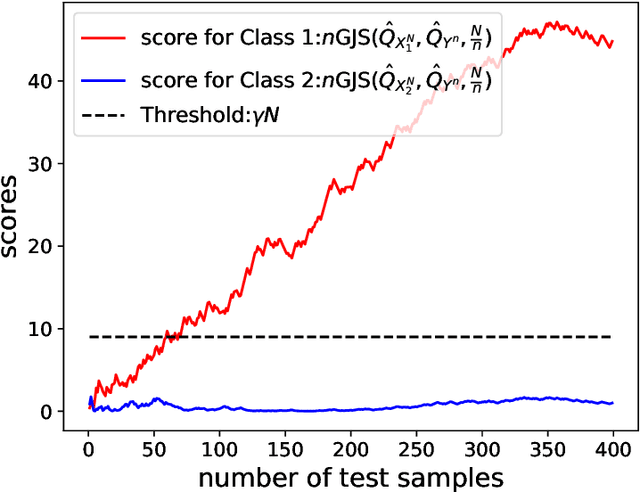



Motivated by real-world machine learning applications, we consider a statistical classification task in a sequential setting where test samples arrive sequentially. In addition, the generating distributions are unknown and only a set of empirically sampled sequences are available to a decision maker. The decision maker is tasked to classify a test sequence which is known to be generated according to either one of the distributions. In particular, for the binary case, the decision maker wishes to perform the classification task with minimum number of the test samples, so, at each step, she declares that either hypothesis 1 is true, hypothesis 2 is true, or she requests for an additional test sample. We propose a classifier and analyze the type-I and type-II error probabilities. We demonstrate the significant advantage of our sequential scheme compared to an existing non-sequential classifier proposed by Gutman. Finally, we extend our setup and results to the multi-class classification scenario and again demonstrate that the variable-length nature of the problem affords significant advantages as one can achieve the same set of exponents as Gutman's fixed-length setting but without having the rejection option.