 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparation of time scales and direct computation of weights in deep neural networks
Paper and Code


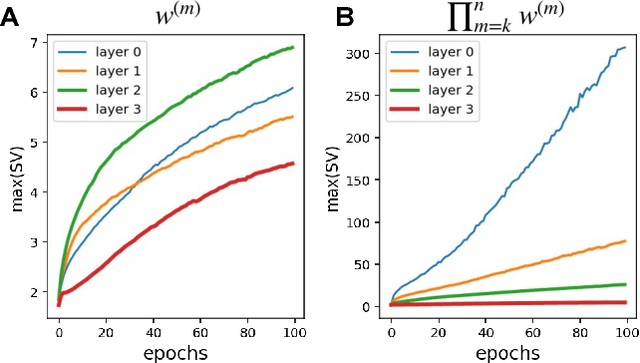

Artificial intelligence is revolutionizing our lives at an ever increasing pace. At the heart of this revolution is the recent advancements in deep neural networks (DNN), learning to perform sophisticated, high-level tasks. However, training DNNs requires massive amounts of data and is very computationally intensive. Gaining analytical understanding of the solutions found by DNNs can help us devise more efficient training algorithms, replacing the commonly used mthod of stochastic gradient descent (SGD). We analyze the dynamics of SGD and show that, indeed, direct computation of the solutions is possible in many cases. We show that a high performing setup used in DNNs introduces a separation of time-scales in the training dynamics, allowing SGD to train layers from the lowest (closest to input) to the highest. We then show that for each layer, the distribution of solutions found by SGD can be estimated using a class-based principal component analysis (PCA) of the layer's input. This finding allows us to forgo SGD entirely and directly derive the DNN parameters using this class-based PCA, which can be well estimated using significantly less data than SGD. We implement these results on image datasets MNIST, CIFAR10 and CIFAR100 and find that, in fact, layers derived using our class-based PCA perform comparable or superior to neural networks of the same size and architecture trained using SGD. We also confirm that the class-based PCA often converges using a fraction of the data required for SGD. Thus, using our method training time can be reduced both by requiring less training data than SGD, and by eliminating layers in the costly backpropagation step of the training.