 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis of Citations Using Word2vec
Paper and Code
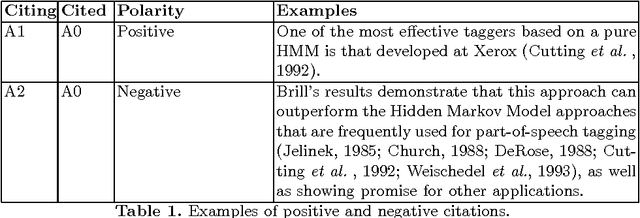



Citation sentiment analysis is an important task in scientific paper analysis. Existing machine learning techniques for citation sentiment analysis are focusing on labor-intensive feature engineering, which requires large annotated corpus. As an automatic feature extraction tool, word2vec has been successfully applied to sentiment analysis of short texts. In this work, I conducted empirical research with the question: how well does word2vec work on the sentiment analysis of citations? The proposed method constructed sentence vectors (sent2vec) by averaging the word embeddings, which were learned from Anthology Collections (ACL-Embeddings). I also investigated polarity-specific word embeddings (PS-Embeddings) for classifying positive and negative citations. The sentence vectors formed a feature space, to which the examined citation sentence was mapped to. Those features were input into classifiers (support vector machines) for supervised classification. Using 10-cross-validation scheme, evaluation was conducted on a set of annotated citations. The results showed that word embeddings are effective on classifying positive and negative citations. However, hand-crafted features performed better for the overall classification.