 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment analysis and random forest to classify LLM versus human source applied to Scientific Texts
Paper and Code
Apr 05, 2024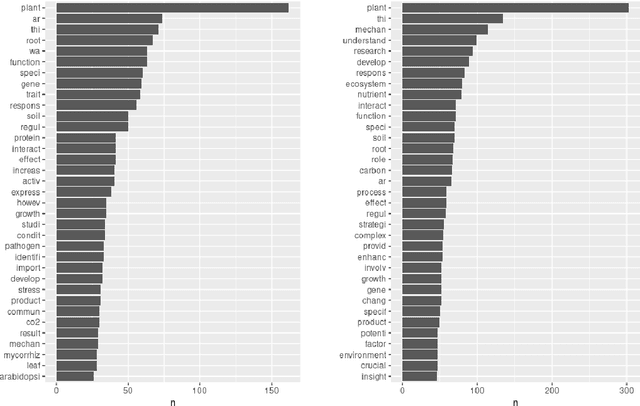
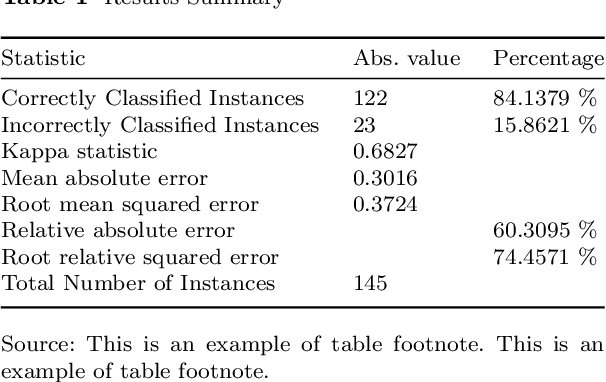
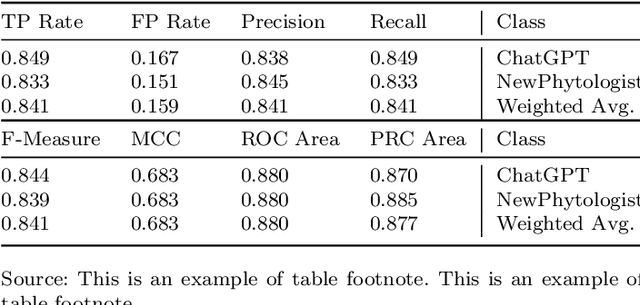
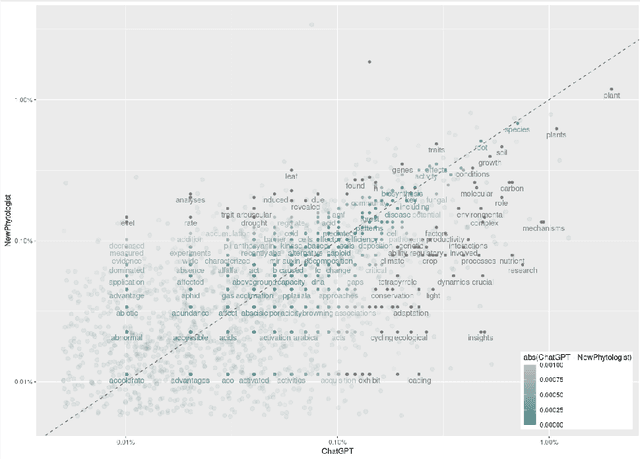
After the launch of ChatGPT v.4 there has been a global vivid discussion on the ability of this artificial intelligence powered platform and some other similar ones for the automatic production of all kinds of texts, including scientific and technical texts. This has triggered a reflection in many institutions on whether education and academic procedures should be adapted to the fact that in future many texts we read will not be written by humans (students, scholars, etc.), at least, not entirely. In this work it is proposed a new methodology to classify texts coming from an automatic text production engine or a human, based on Sentiment Analysis as a source for feature engineering independent variables and then train with them a Random Forest classification algorithm. Using four different sentiment lexicons, a number of new features where produced, and then fed to a machine learning random forest methodology, to train such a model. Results seem very convincing that this may be a promising research line to detect fraud, in such environments where human are supposed to be the source of texts.