 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemisupervised Neural Proto-Language Reconstruction
Paper and Code
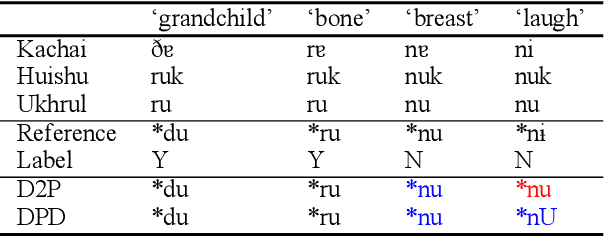
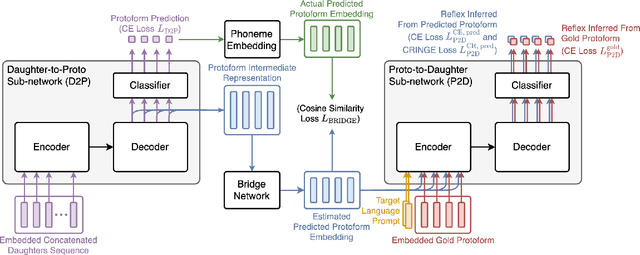
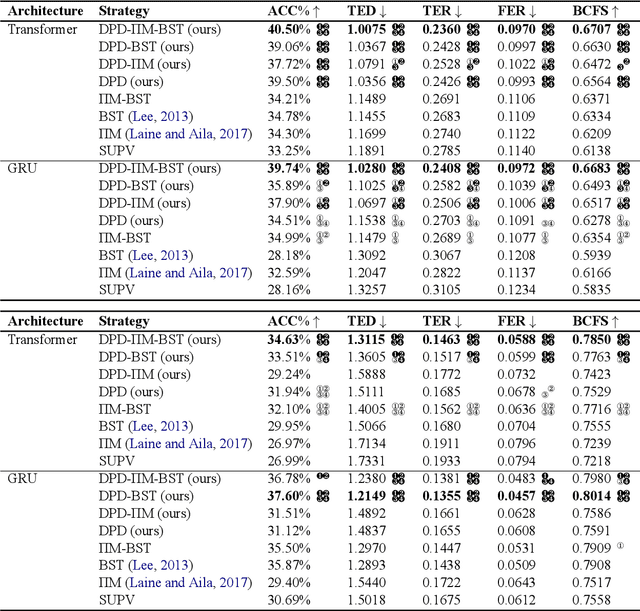
Existing work implementing comparative reconstruction of ancestral languages (proto-languages) has usually required full supervision. However, historical reconstruction models are only of practical value if they can be trained with a limited amount of labeled data. We propose a semisupervised historical reconstruction task in which the model is trained on only a small amount of labeled data (cognate sets with proto-forms) and a large amount of unlabeled data (cognate sets without proto-forms). We propose a neural architecture for comparative reconstruction (DPD-BiReconstructor) incorporating an essential insight from linguists' comparative method: that reconstructed words should not only be reconstructable from their daughter words, but also deterministically transformable back into their daughter words. We show that this architecture is able to leverage unlabeled cognate sets to outperform strong semisupervised baselines on this novel task.