 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically-enhanced Deep Collision Prediction for Autonomous Navigation using Aerial Robots
Paper and Code
Jul 21, 2023

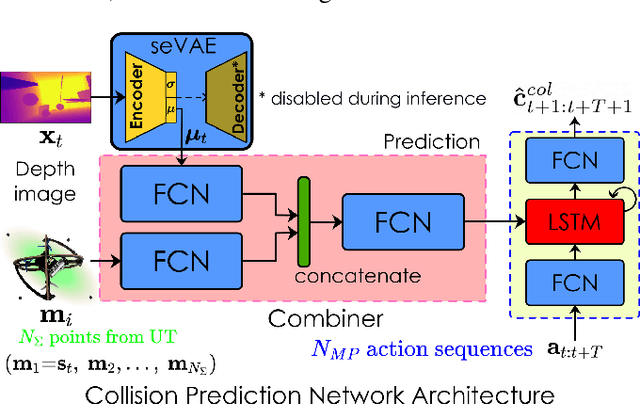

This paper contributes a novel and modularized learning-based method for aerial robots navigating cluttered environments containing hard-to-perceive thin obstacles without assuming access to a map or the full pose estimation of the robot. The proposed solution builds upon a semantically-enhanced Variational Autoencoder that is trained with both real-world and simulated depth images to compress the input data, while preserving semantically-labeled thin obstacles and handling invalid pixels in the depth sensor's output. This compressed representation, in addition to the robot's partial state involving its linear/angular velocities and its attitude are then utilized to train an uncertainty-aware 3D Collision Prediction Network in simulation to predict collision scores for candidate action sequences in a predefined motion primitives library. A set of simulation and experimental studies in cluttered environments with various sizes and types of obstacles, including multiple hard-to-perceive thin objects, were conducted to evaluate the performance of the proposed method and compare against an end-to-end trained baseline. The results demonstrate the benefits of the proposed semantically-enhanced deep collision prediction for learning-based autonomous navigation.