 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Based Explainable AI: Leveraging Semantic Scene Graphs and Pairwise Ranking to Explain Robot Failures
Paper and Code
Aug 08, 2021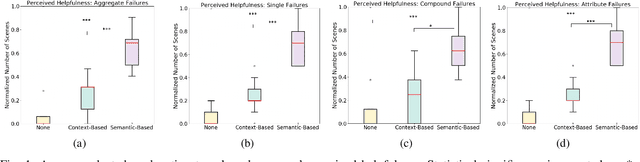
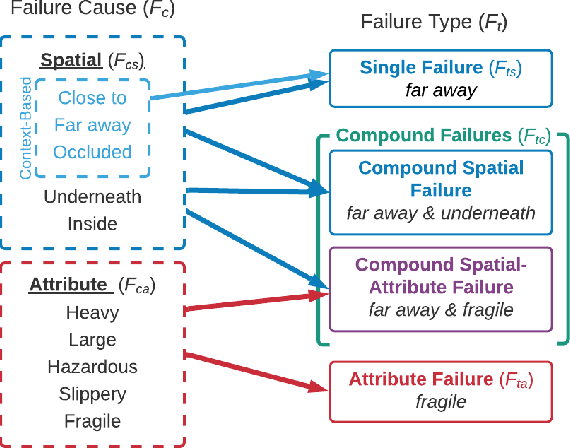
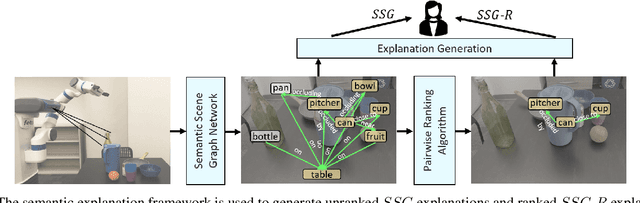

When interacting in unstructured human environments, occasional robot failures are inevitable. When such failures occur, everyday people, rather than trained technicians, will be the first to respond. Existing natural language explanations hand-annotate contextual information from an environment to help everyday people understand robot failures. However, this methodology lacks generalizability and scalability. In our work, we introduce a more generalizable semantic explanation framework. Our framework autonomously captures the semantic information in a scene to produce semantically descriptive explanations for everyday users. To generate failure-focused explanations that are semantically grounded, we leverages both semantic scene graphs to extract spatial relations and object attributes from an environment, as well as pairwise ranking. Our results show that these semantically descriptive explanations significantly improve everyday users' ability to both identify failures and provide assistance for recovery than the existing state-of-the-art context-based explanations.