 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Autoencoder and Its Potential Usage for Adversarial Attack
Paper and Code

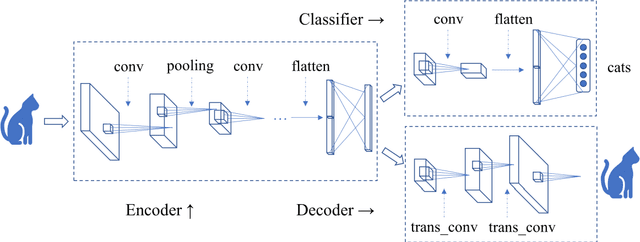
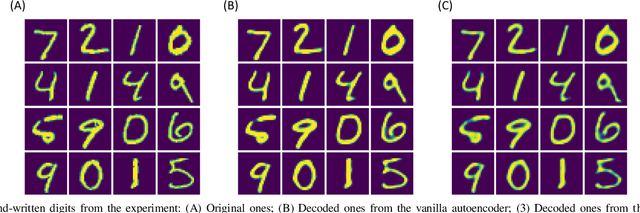
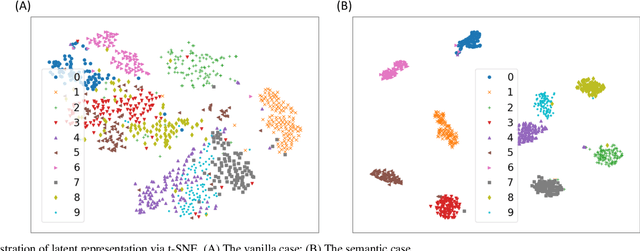
Autoencoder can give rise to an appropriate latent representation of the input data, however, the representation which is solely based on the intrinsic property of the input data, is usually inferior to express some semantic information. A typical case is the potential incapability of forming a clear boundary upon clustering of these representations. By encoding the latent representation that not only depends on the content of the input data, but also the semantic of the input data, such as label information, we propose an enhanced autoencoder architecture named semantic autoencoder. Experiments of representation distribution via t-SNE shows a clear distinction between these two types of encoders and confirm the supremacy of the semantic one, whilst the decoded samples of these two types of autoencoders exhibit faint dissimilarity either objectively or subjectively. Based on this observation, we consider adversarial attacks to learning algorithms that rely on the latent representation obtained via autoencoders. It turns out that latent contents of adversarial samples constructed from semantic encoder with deliberate wrong label information exhibit different distribution compared with that of the original input data, while both of these samples manifest very marginal difference. This new way of attack set up by our work is worthy of attention due to the necessity to secure the widespread deep learning applications.