 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Abstraction: Open-World 3D Scene Understanding from 2D Vision-Language Models
Paper and Code
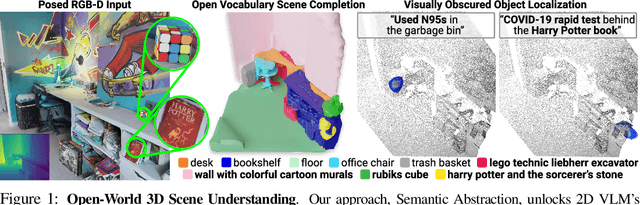
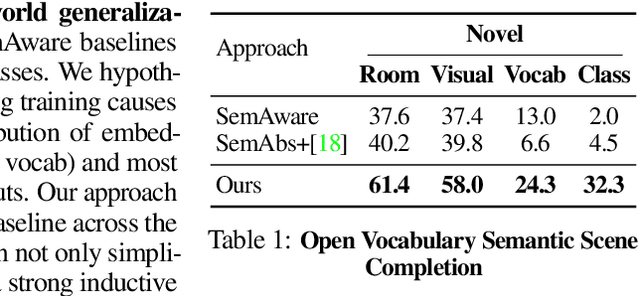
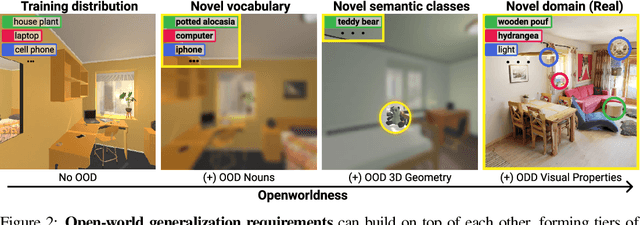
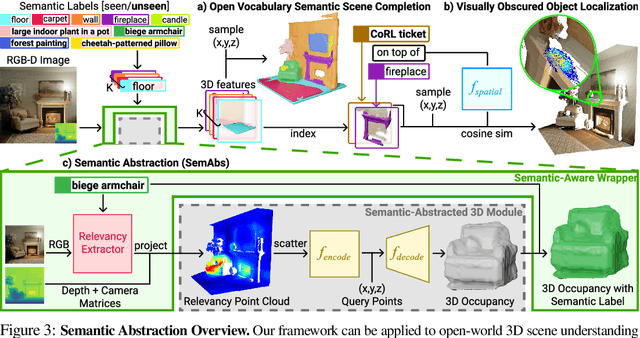
We study open-world 3D scene understanding, a family of tasks that require agents to reason about their 3D environment with an open-set vocabulary and out-of-domain visual inputs - a critical skill for robots to operate in the unstructured 3D world. Towards this end, we propose Semantic Abstraction (SemAbs), a framework that equips 2D Vision-Language Models (VLMs) with new 3D spatial capabilities, while maintaining their zero-shot robustness. We achieve this abstraction using relevancy maps extracted from CLIP, and learn 3D spatial and geometric reasoning skills on top of those abstractions in a semantic-agnostic manner. We demonstrate the usefulness of SemAbs on two open-world 3D scene understanding tasks: 1) completing partially observed objects and 2) localizing hidden objects from language descriptions. Experiments show that SemAbs can generalize to novel vocabulary, materials/lighting, classes, and domains (i.e., real-world scans) from training on limited 3D synthetic data. Code and data will be available at https://semantic-abstraction.cs.columbia.edu/