 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Representations Improve End-to-End Speech Translation
Paper and Code
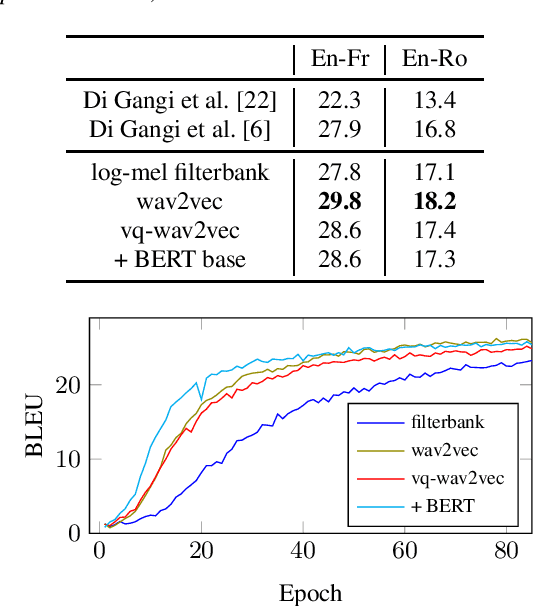
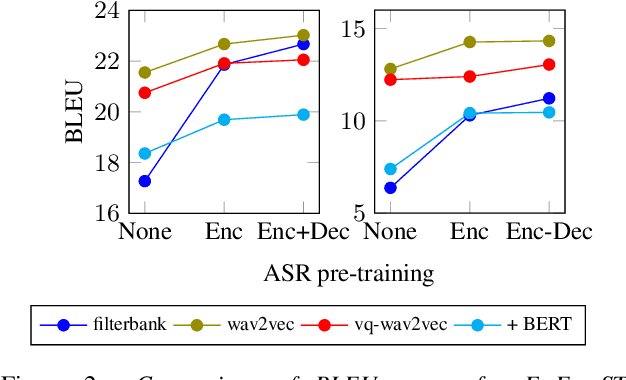

End-to-end speech-to-text translation can provide a simpler and smaller system but is facing the challenge of data scarcity. Pre-training methods can leverage unlabeled data and have been shown to be effective on data-scarce settings. In this work, we explore whether self-supervised pre-trained speech representations can benefit the speech translation task in both high- and low-resource settings, whether they can transfer well to other languages, and whether they can be effectively combined with other common methods that help improve low-resource end-to-end speech translation such as using a pre-trained high-resource speech recognition system. We demonstrate that self-supervised pre-trained features can consistently improve the translation performance, and cross-lingual transfer allows to extend to a variety of languages without or with little tuning.