 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Perceptually Optimized Block Motion Estimates for Video Compression
Paper and Code
Oct 11, 2021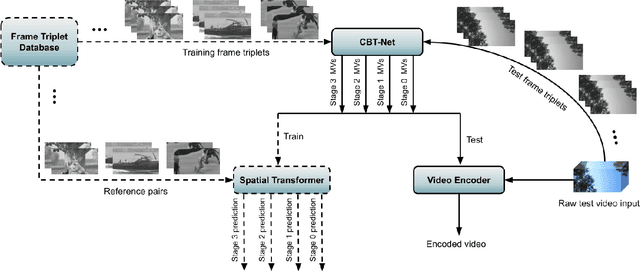


Block based motion estimation is integral to inter prediction processes performed in hybrid video codecs. Prevalent block matching based methods that are used to compute block motion vectors (MVs) rely on computationally intensive search procedures. They also suffer from the aperture problem, which can worsen as the block size is reduced. Moreover, the block matching criteria used in typical codecs do not account for the resulting levels of perceptual quality of the motion compensated pictures that are created upon decoding. Towards achieving the elusive goal of perceptually optimized motion estimation, we propose a search-free block motion estimation framework using a multi-stage convolutional neural network, which is able to conduct motion estimation on multiple block sizes simultaneously, using a triplet of frames as input. This composite block translation network (CBT-Net) is trained in a self-supervised manner on a large database that we created from publicly available uncompressed video content. We deploy the multi-scale structural similarity (MS-SSIM) loss function to optimize the perceptual quality of the motion compensated predicted frames. Our experimental results highlight the computational efficiency of our proposed model relative to conventional block matching based motion estimation algorithms, for comparable prediction errors. Further, when used to perform inter prediction in AV1, the MV predictions of the perceptually optimized model result in average Bjontegaard-delta rate (BD-rate) improvements of -1.70% and -1.52% with respect to the MS-SSIM and Video Multi-Method Assessment Fusion (VMAF) quality metrics, respectively as compared to the block matching based motion estimation system employed in the SVT-AV1 encoder.