 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning from Web Data for Multimodal Retrieval
Paper and Code


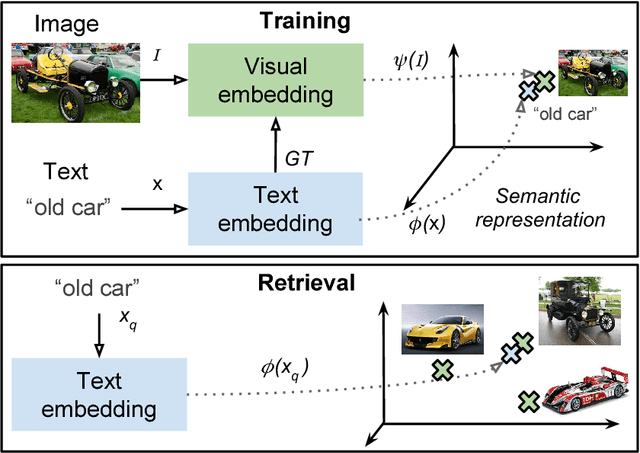
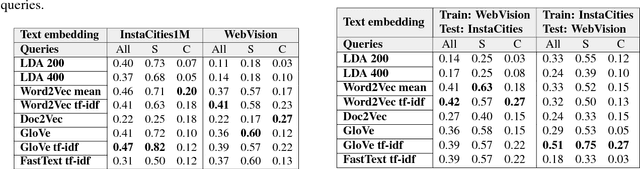
Self-Supervised learning from multimodal image and text data allows deep neural networks to learn powerful features with no need of human annotated data. Web and Social Media platforms provide a virtually unlimited amount of this multimodal data. In this work we propose to exploit this free available data to learn a multimodal image and text embedding, aiming to leverage the semantic knowledge learnt in the text domain and transfer it to a visual model for semantic image retrieval. We demonstrate that the proposed pipeline can learn from images with associated textwithout supervision and analyze the semantic structure of the learnt joint image and text embedding space. We perform a thorough analysis and performance comparison of five different state of the art text embeddings in three different benchmarks. We show that the embeddings learnt with Web and Social Media data have competitive performances over supervised methods in the text based image retrieval task, and we clearly outperform state of the art in the MIRFlickr dataset when training in the target data. Further, we demonstrate how semantic multimodal image retrieval can be performed using the learnt embeddings, going beyond classical instance-level retrieval problems. Finally, we present a new dataset, InstaCities1M, composed by Instagram images and their associated texts that can be used for fair comparison of image-text embeddings.