 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Human Activity Recognition by Augmenting Generative Adversarial Networks
Paper and Code
Aug 26, 2020
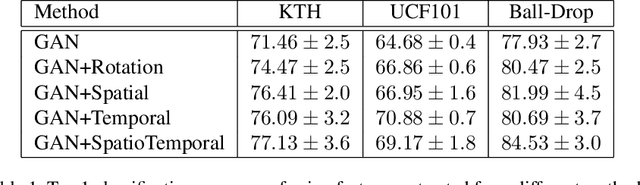

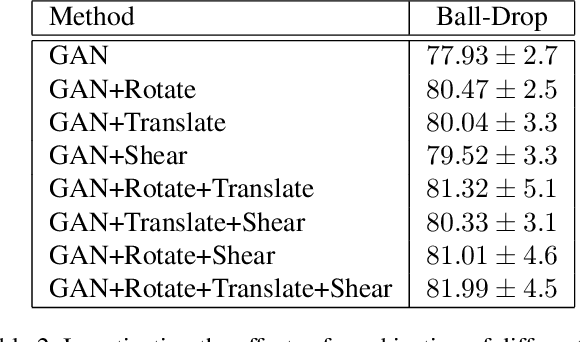
This article proposes a novel approach for augmenting generative adversarial network (GAN) with a self-supervised task in order to improve its ability for encoding video representations that are useful in downstream tasks such as human activity recognition. In the proposed method, input video frames are randomly transformed by different spatial transformations, such as rotation, translation and shearing or temporal transformations such as shuffling temporal order of frames. Then discriminator is encouraged to predict the applied transformation by introducing an auxiliary loss. Subsequently, results prove superiority of the proposed method over baseline methods for providing a useful representation of videos used in human activity recognition performed on datasets such as KTH, UCF101 and Ball-Drop. Ball-Drop dataset is a specifically designed dataset for measuring executive functions in children through physically and cognitively demanding tasks. Using features from proposed method instead of baseline methods caused the top-1 classification accuracy to increase by more then 4%. Moreover, ablation study was performed to investigate the contribution of different transformations on downstream task.