 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Class Incremental Learning
Paper and Code
Nov 18, 2021
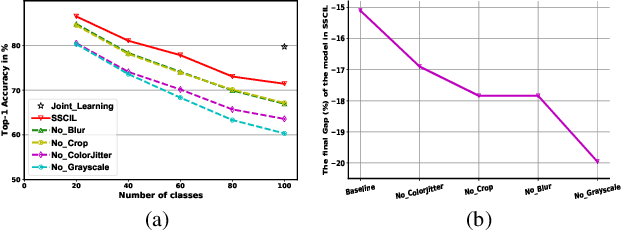
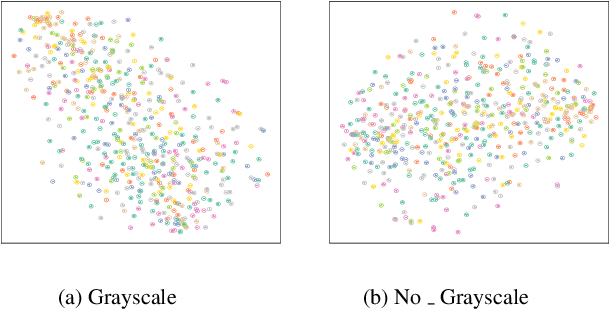
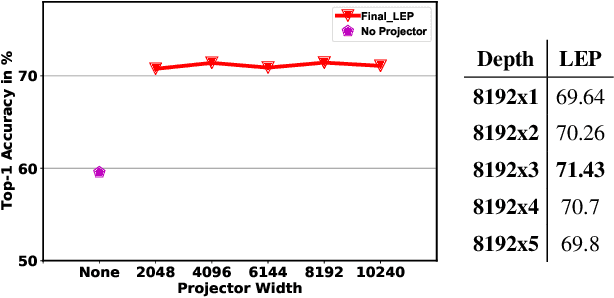
Existing Class Incremental Learning (CIL) methods are based on a supervised classification framework sensitive to data labels. When updating them based on the new class data, they suffer from catastrophic forgetting: the model cannot discern old class data clearly from the new. In this paper, we explore the performance of Self-Supervised representation learning in Class Incremental Learning (SSCIL) for the first time, which discards data labels and the model's classifiers. To comprehensively discuss the difference in performance between supervised and self-supervised methods in CIL, we set up three different class incremental schemes: Random Class Scheme, Semantic Class Scheme, and Cluster Scheme, to simulate various class incremental learning scenarios. Besides, we propose Linear Evaluation Protocol (LEP) and Generalization Evaluation Protocol (GEP) to metric the model's representation classification ability and generalization in CIL. Our experiments (on ImageNet-100 and ImageNet) show that SSCIL has better anti-forgetting ability and robustness than supervised strategies in CIL. To understand what alleviates the catastrophic forgetting in SSCIL, we study the major components of SSCIL and conclude that (1) the composition of different data augmentation improves the quality of the model's representation and the \textit{Grayscale} operation reduces the system noise of data augmentation in SSCIL. (2) the projector, like a buffer, reduces unnecessary parameter updates of the model in SSCIL and increases the robustness of the model. Although the performance of SSCIL is significantly higher than supervised methods in CIL, there is still an apparent gap with joint learning. Our exploration gives a baseline of self-supervised class incremental learning on large-scale datasets and contributes some forward strategies for mitigating the catastrophic forgetting in CIL.