 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-SuperFlow: Self-supervised Scene Flow Prediction in Stereo Sequences
Paper and Code
Jun 30, 2022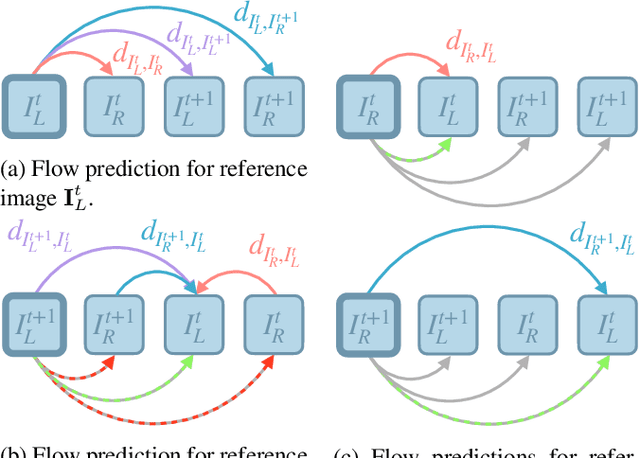


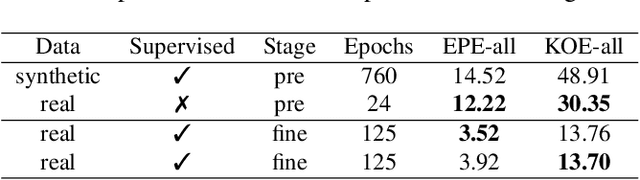
In recent years, deep neural networks showed their exceeding capabilities in addressing many computer vision tasks including scene flow prediction. However, most of the advances are dependent on the availability of a vast amount of dense per pixel ground truth annotations, which are very difficult to obtain for real life scenarios. Therefore, synthetic data is often relied upon for supervision, resulting in a representation gap between the training and test data. Even though a great quantity of unlabeled real world data is available, there is a huge lack in self-supervised methods for scene flow prediction. Hence, we explore the extension of a self-supervised loss based on the Census transform and occlusion-aware bidirectional displacements for the problem of scene flow prediction. Regarding the KITTI scene flow benchmark, our method outperforms the corresponding supervised pre-training of the same network and shows improved generalization capabilities while achieving much faster convergence.