 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-augmented Data Selection for Few-shot Dialogue Generation
Paper and Code
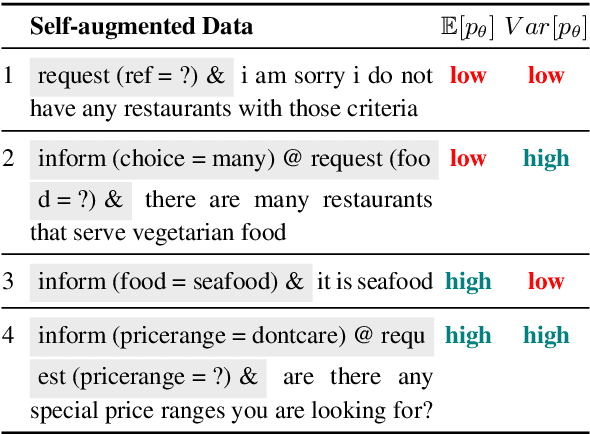
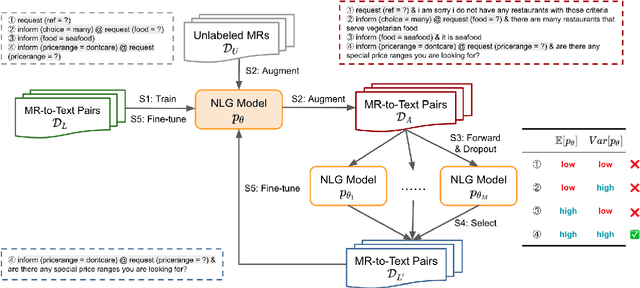

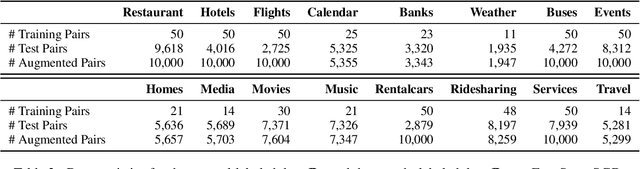
The natural language generation (NLG) module in task-oriented dialogue systems translates structured meaning representations (MRs) into text responses, which has a great impact on users' experience as the human-machine interaction interface. However, in practice, developers often only have a few well-annotated data and confront a high data collection cost to build the NLG module. In this work, we adopt the self-training framework to deal with the few-shot MR-to-Text generation problem. We leverage the pre-trained language model to self-augment many pseudo-labeled data. To prevent the gradual drift from target data distribution to noisy augmented data distribution, we propose a novel data selection strategy to select the data that our generation model is most uncertain about. Compared with existing data selection methods, our method is: (1) parameter-efficient, which does not require training any additional neural models, (2) computation-efficient, which only needs to apply several stochastic forward passes of the model to estimate the uncertainty. We conduct empirical experiments on two benchmark datasets: FewShotWOZ and FewShotSGD, and show that our proposed framework consistently outperforms other baselines in terms of BLEU and ERR.