 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Pseudo-labeling and Class-wise Discriminative Fusion for Sound Event Detection
Paper and Code
Mar 04, 2022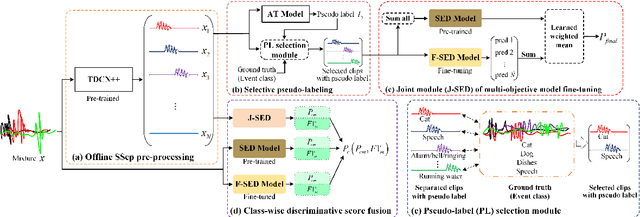
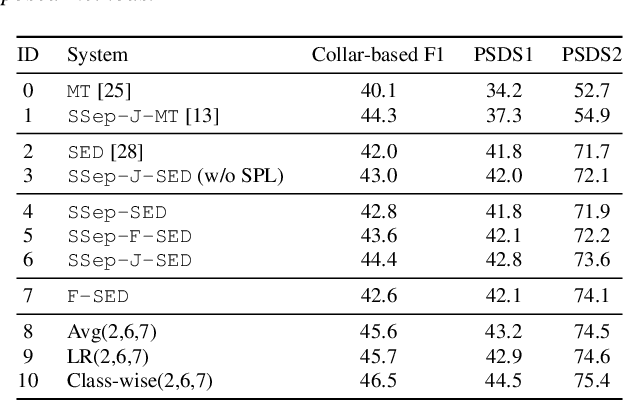
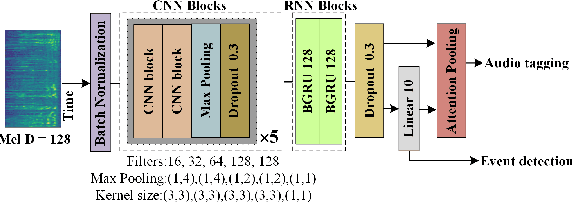
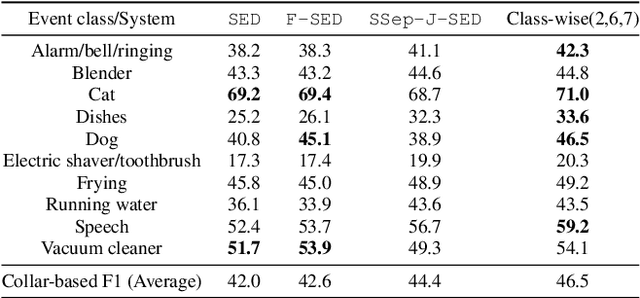
In recent years, exploring effective sound separation (SSep) techniques to improve overlapping sound event detection (SED) attracts more and more attention. Creating accurate separation signals to avoid the catastrophic error accumulation during SED model training is very important and challenging. In this study, we first propose a novel selective pseudo-labeling approach, termed SPL, to produce high confidence separated target events from blind sound separation outputs. These target events are then used to fine-tune the original SED model that pre-trained on the sound mixtures in a multi-objective learning style. Then, to further leverage the SSep outputs, a class-wise discriminative fusion is proposed to improve the final SED performances, by combining multiple frame-level event predictions of both sound mixtures and their separated signals. All experiments are performed on the public DCASE 2021 Task 4 dataset, and results show that our approaches significantly outperforms the official baseline, the collar-based F 1, PSDS1 and PSDS2 performances are improved from 44.3%, 37.3% and 54.9% to 46.5%, 44.5% and 75.4%, respectively.