 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Classification via Curve Optimization
Paper and Code
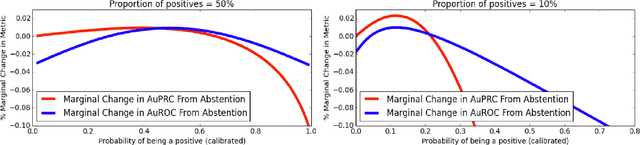
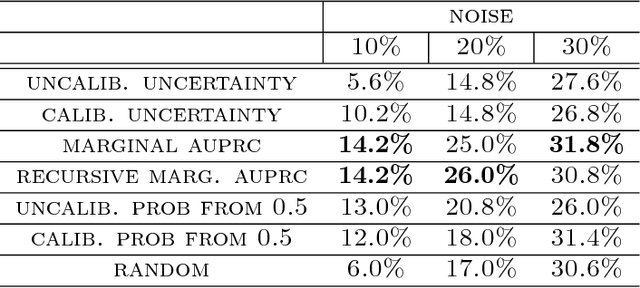
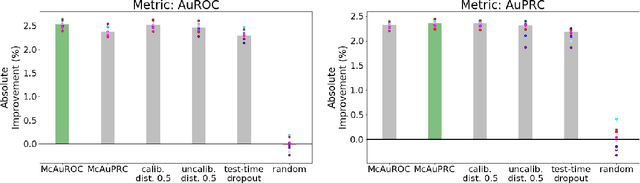
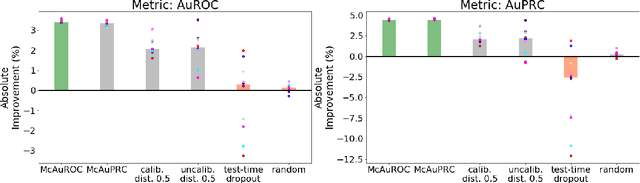
In practical applications of machine learning, it is often desirable to identify and abstain on examples where the model's predictions are likely to be incorrect. We consider the problem of selecting a budget-constrained subset of test examples to abstain on, with the goal of maximizing performance on the remaining examples. We develop a novel approach to this problem by analytically optimizing the expected marginal improvement in a desired performance metric, such as the area under the ROC curve or Precision-Recall curve. We compare our approach to other abstention techniques for deep learning models based on posterior probability and uncertainty estimates obtained using test-time dropout. On various tasks in computer vision, natural language processing, and bioinformatics, we demonstrate the consistent effectiveness of our approach over other techniques.